This is archived documentation for InfluxData product versions that are no longer maintained. For newer documentation, see the latest InfluxData documentation.
Known Issues
- Why are my Grafana panels returning truncated/partial data?
- Why do queries that use math on several selector functions return more than one point?
- What should I do if I see the panic:
unexpected fault address xxxxxxxxxxxxxx?
Log Errors
- Why am I seeing a
503 Service Unavailableerror in my meta node logs? - Why am I seeing a
409error in some of my data node logs? - Why am I seeing
hinted handoff queue not emptyerrors in my data node logs? - Why am I seeing
error writing count stats ...: partial writeerrors in my data node logs? - Why am I seeing
queue is fullerrors in my data node logs? - Why am I seeing
unable to determine if "hostname" is a meta nodewhen I try to add a meta node withinfluxd-ctl join? - Why am I getting a Basic Authentication pop-up window from my InfluxEnterprise Web Console?
Other
Why are my Grafana panels returning truncated/partial data?
In InfluxEnterprise versions 1.2.0-1.2.2, the system sets the max-row-limit configuration option to 10,000 by default.
That option limits the number of rows returned per query to 10,000 rows.
If a query in Grafana exceeds that 10,000 row limit, the panel appears to show truncated data.
To prevent that issue, set max-row-limit to 0 to allow an unlimited number of returned rows.
This issue is fixed in version 1.2.5.
In version 1.2.5, the configuration file sets max-row-limit to 0 by default.
Why do queries that use math on several selector functions return more than one point?
In InfluxEnterprise versions prior to 1.2.0, queries that use math on several selector functions return one point with the epoch 0 (1970-01-01T00:00:00Z) timestamp.
In versions 1.2.0-1.2.2, those queries return N points, where N is the number of unique timestamps returned by the individual selector functions.
As a workaround, use InfluxQL’s subqueries in versions 1.2.0-1.2.2 to replicate the query behavior in versions prior to 1.2.0.
This issue is fixed in version 1.2.5.
Example
The queries below perform multiplication on two selector functions.
Behavior in versions prior to 1.2.0:
> SELECT MIN("avocado")*2,MAX("avocado")*2 FROM "mycart"
name: mycart
time min max
---- --- ---
0 24 46
The query returns a single point with the epoch 0 timestamp.
Behavior in versions 1.2.0-1.2.2:
> SELECT MIN("avocado")*2,MAX("avocado")*2 FROM "mycart"
name: mycart
time min max
---- --- ---
1490113486589201368 24
1490113497387418180 46
The query returns two points; one point for each timestamp returned by the individual selector functions.
Workaround for versions 1.2.0-1.2.2:
> SELECT "min"*2,"max"*2 FROM (SELECT MIN("avocado"),MAX("avocado") FROM "mycart")
name: mycart
time min max
---- --- ---
0 24 46
The workaround uses InfluxQL’s subqueries to replicate the query behavior in versions prior to 1.2.0.
What should I do if I see the panic: unexpected fault address xxxxxxxxxxxxxx?
In InfluxEnterprise versions 1.2.0-1.2.2, there is a known issue where the data node process stops and reports the panic unexpected fault address xxxxxxxxxxxxxx in the logs.
If you experience this panic please restart the data node process.
We are working to address this issue; see GitHub Issue #8022 for additional information.
This issue is fixed in version 1.2.5.
Where can I find InfluxEnterprise logs?
On systemd operating systems service logs can be accessed using the journalctl command.
Meta: journalctl -u influxdb-meta
Data : journalctl -u influxdb
Enterprise console: journalctl -u influx-enterprise
The journalctl output can be redirected to print the logs to a text file. With systemd, log retention depends on the system’s journald settings.
Why am I seeing a 503 Service Unavailable error in my meta node logs?
This is the expected behavior if you haven’t joined the meta node to the
cluster.
The 503 errors should stop showing up in the logs once you
join
the meta node to the cluster.
Why am I seeing a 409 error in some of my data node logs?
When you create a
Continuous Query (CQ)
on your cluster every data node will ask for the CQ lease.
Only one data node can accept the lease.
That data node will have a 200 in its logs.
All other data nodes will be denied the lease and have a 409 in their logs.
This is the expected behavior.
Log output for a data node that is denied the lease:
[meta-http] 2016/09/19 09:08:53 172.31.4.132 - - [19/Sep/2016:09:08:53 +0000] GET /lease?name=continuous_querier&node_id=5 HTTP/1.2 409 105 - InfluxDB Meta Client b00e4943-7e48-11e6-86a6-000000000000 380.542µs
Log output for the data node that accepts the lease:
[meta-http] 2016/09/19 09:08:54 172.31.12.27 - - [19/Sep/2016:09:08:54 +0000] GET /lease?name=continuous_querier&node_id=0 HTTP/1.2 200 105 - InfluxDB Meta Client b05a3861-7e48-11e6-86a7-000000000000 8.87547ms
Why am I seeing hinted handoff queue not empty errors in my data node logs?
[write] 2016/10/18 10:35:21 write failed for shard 2382 on node 4: hinted handoff queue not empty
This error is informational only and does not necessarily indicate a problem in the cluster. It indicates that the node handling the write request currently has data in its local hinted handoff queue for the destination node. Coordinating nodes will not attempt direct writes to other nodes until the hinted handoff queue for the destination node has fully drained. New data is instead appended to the hinted handoff queue. This helps data arrive in chronological order for consistency of graphs and alerts and also prevents unnecessary failed connection attempts between the data nodes. Until the hinted handoff queue is empty this message will continue to display in the logs. Monitor the size of the hinted handoff queues with ls -lRh /var/lib/influxdb/hh to ensure that they are decreasing in size.
Note that for some write consistency settings, InfluxDB may return a write error (500) for the write attempt, even if the points are successfully queued in hinted handoff. Some write clients may attempt to resend those points, leading to duplicate points being added to the hinted handoff queue and lengthening the time it takes for the queue to drain. If the queues are not draining, consider temporarily downgrading the write consistency setting, or pause retries on the write clients until the hinted handoff queues fully drain.
Why am I seeing error writing count stats ...: partial write errors in my data node logs?
[stats] 2016/10/18 10:35:21 error writing count stats for FOO_grafana: partial write
The _internal database collects per-node and also cluster-wide information about the InfluxEnterprise cluster. The cluster metrics are replicated to other nodes using consistency=all. For a write consistency of all, InfluxDB returns a write error (500) for the write attempt even if the points are successfully queued in hinted handoff. Thus, if there are points still in hinted handoff, the _internal writes will fail the consistency check and log the error, even though the data is in the durable hinted handoff queue and should eventually persist.
Why am I seeing queue is full errors in my data node logs?
This error indicates that the coordinating node that received the write cannot add the incoming write to the hinted handoff queue for the destination node because it would exceed the maximum size of the queue. This error typically indicates a catastrophic condition for the cluster - one data node may have been offline or unable to accept writes for an extended duration.
The controlling configuration settings are in the [hinted-handoff] section of the file. max-size is the total size in bytes per hinted handoff queue. When max-size is exceeded, all new writes for that node are rejected until the queue drops below max-size. max-age is the maximum length of time a point will persist in the queue. Once this limit has been reached, points expire from the queue. The age is calculated from the write time of the point, not the timestamp of the point.
Why am I seeing unable to determine if "hostname" is a meta node when I try to add a meta node with influxd-ctl join?
Meta nodes use the /status endpoint to determine the current state of another metanode. A healthy meta node that is ready to join the cluster will respond with a 200 HTTP response code and a JSON string with the following format (assuming the default ports):
"nodeType":"meta","leader":"","httpAddr":"<hostname>:8091","raftAddr":"<hostname>:8089","peers":null}
If you are getting an error message while attempting to influxd-ctl join a new meta node, it means that the JSON string returned from the /status endpoint is incorrect. This generally indicates that the meta node configuration file is incomplete or incorrect. Inspect the HTTP response with curl -v "http://<hostname>:8091/status" and make sure that the hostname, the bind-address, and the http-bind-address are correctly populated. Also check the license-key or license-path in the configuration file of the meta nodes. Finally, make sure that you specify the http-bind-address port in the join command, e.g. influxd-ctl join hostname:8091.
Why am I getting a Basic Authentication pop-up window from my InfluxEnterprise Web Console?
The InfluxEnterprise Web Console will create a popup requesting Authentication credentials when the shared-secret configured under the [influxdb] section in the influx-enterprise.conf Web Console configuration file does not match with the shared-secret configured under the [http] section in all data node influxdb.conf configuration files. All data nodes and the InfluxEnteprise Web Console must share the same passphrase.
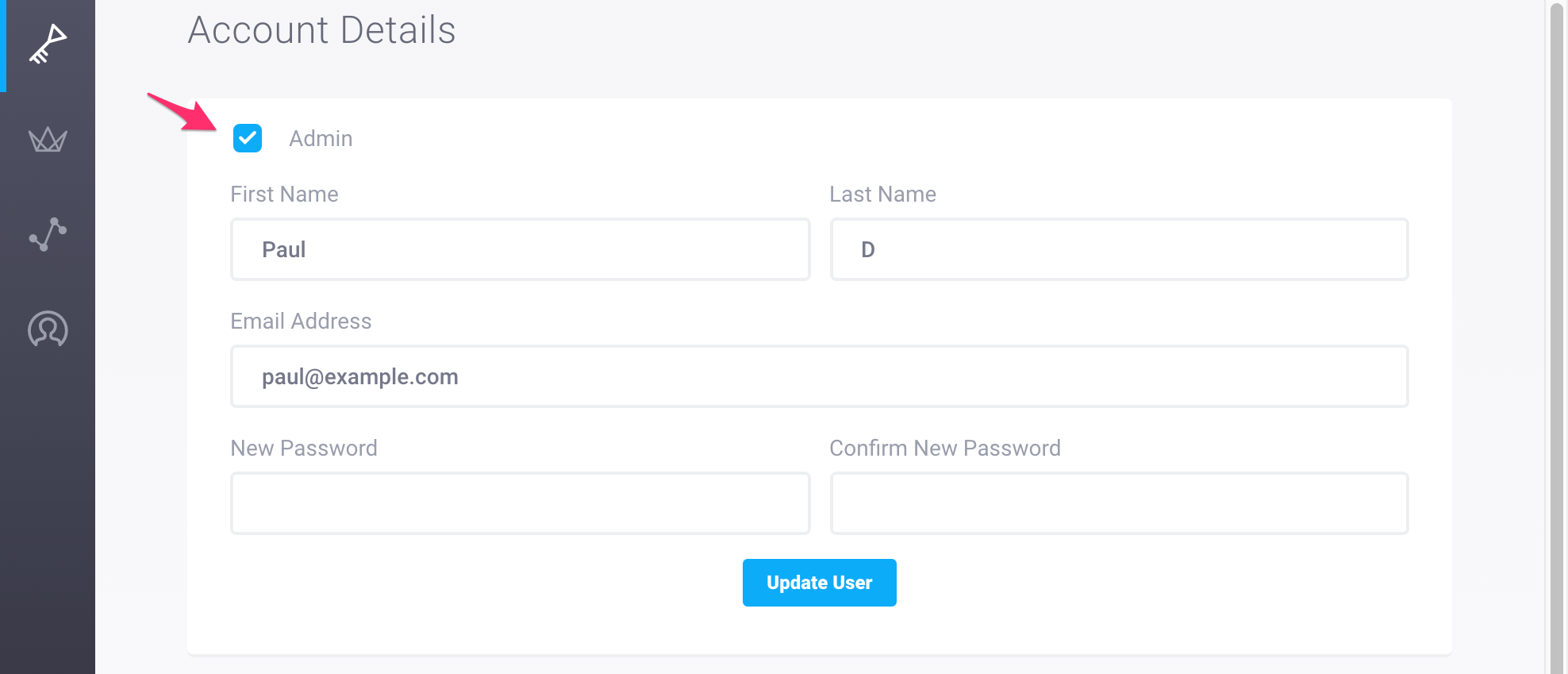
How do I make a web console user an admin web console user?
Web console users can be admin users or non-admin users. In addition to having access to the web console, admin users are able to invite users, manage web console users, manage cluster accounts, and edit cluster names.
By default, new web console users are non-admin users.
To make a web console user an admin user, visit the Users page located in the
WEB ADMIN section in the sidebar and click on the name of the relevant user.
In the Account Details section, select the checkbox next to Admin and click
Update User.