This is archived documentation for InfluxData product versions that are no longer maintained. For newer documentation, see the latest InfluxData documentation.
This guide offers general hardware recommendations for InfluxDB and addresses some frequently asked questions about hardware sizing. The recommendations are only for the Time Structured Merge tree (TSM) storage engine, the only storage engine available with InfluxDB 0.11. Users running older versions of InfluxDB with unconverted b1 or bz1 shards may have different performance characteristics. See the InfluxDB 0.9 sizing guide for more detail.
Single node:
- General hardware guidelines for a single node
- When do I need more RAM?
- What kind of storage do I need?
- How much storage do I need?
- How should I configure my hardware?
Clustering:
- General hardware guidelines for clusters
- How should I configure my hardware differently form a single-node instance?
General hardware guidelines for a single node
We define the load that you’ll be placing on InfluxDB by the number of writes per second, the number of queries per second, and the number of unique series. Based on your load, we make general CPU, RAM, and IOPS recommendations.
| Load | Writes per second | Queries per second | Unique series |
|---|---|---|---|
| Low | < 5 thousand | < 5 | < 100 thousand |
| Moderate | < 100 thousand | < 25 | < 1 million |
| High | > 100 thousand | > 25 | > 1 million |
| Probably infeasible | > 500 thousand | > 100 | > 10 million |
Low load recommendations
- CPU: 2-4
- RAM: 2-4 GB
- IOPS: 500
Moderate load recommendations
- CPU: 4-6
- RAM: 8-32GB
- IOPS: 500-1000
High load recommendations
- CPU: 8+
- RAM: 32+ GB
- IOPS: 1000+
Probably infeasible load
Performance at this scale is a significant challenge and may not be achievable. Please contact us at sales@influxdb.com for assistance with tuning your systems.
When do I need more RAM?
In general, having more RAM helps queries return faster. There is no known downside to adding more RAM.
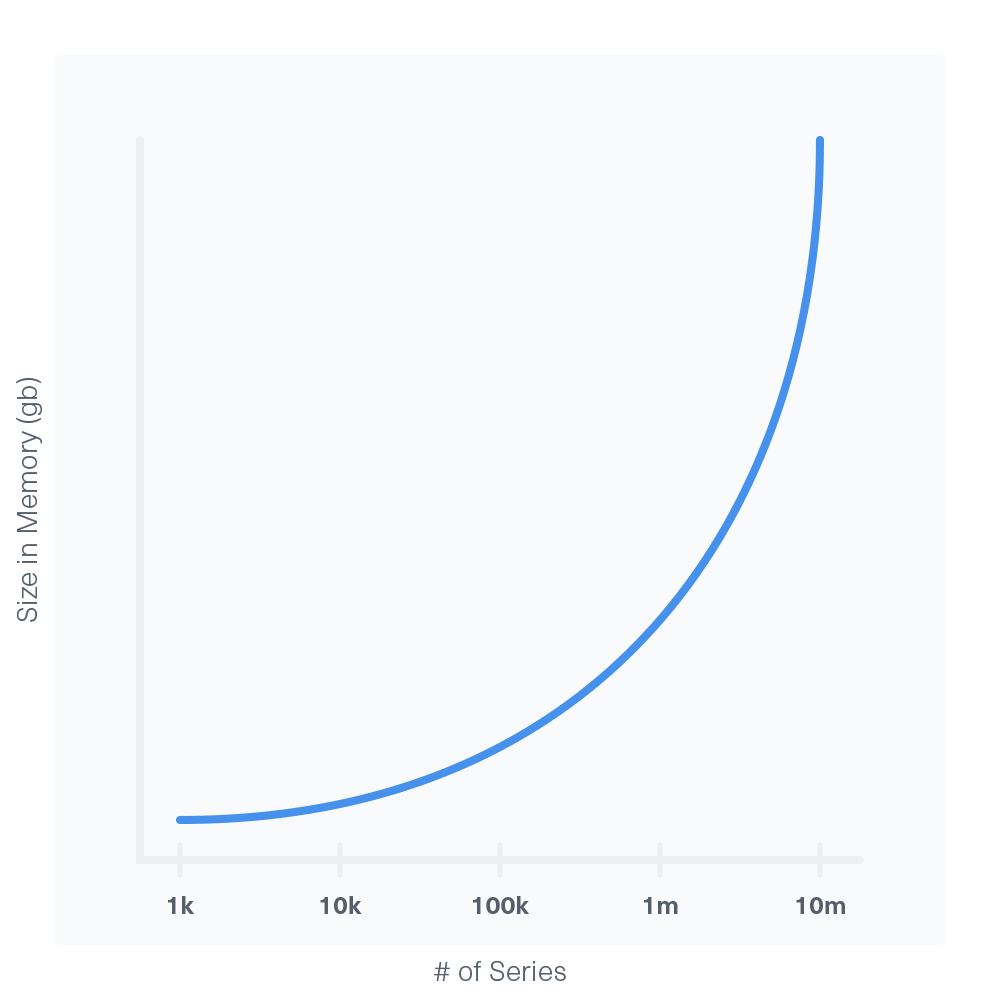
The major component that affects your RAM needs is series cardinality. Series cardinality is the total number of series in a database. If you have one measurement with two tags, and each tag has 1,000 possible values then the series cardinality is 1 million. A series cardinality around or above 10 million can cause OOM failures even with large amounts of RAM. If this is the case, you can usually address the problem by redesigning your schema.
The increase in RAM needs relative to series cardinality is exponential where the exponent is between one and two:
What kind of storage do I need?
InfluxDB is designed to run on SSDs. Performance is lower on spinning disk drives and may not function properly under increasing loads.
How much storage do I need?
Database names, measurements, tag keys, field keys, and tag values are stored only once and always as strings. Only field values and timestamps are stored per-point.
Non-string values require approximately three bytes. String values require variable space as determined by string compression.
How should I configure my hardware?
When running InfluxDB in a production environment the wal directory and the data directory should be on separate storage devices. This optimization significantly reduces disk contention when the system is under heavy write load. This is an important consideration if the write load is highly variable. If the write load does not vary by more than 15% the optimization is probably unneeded.
General hardware guidelines for clusters
NOTE: InfluxDB 0.11 is the last open source version that includes clustering. For more information, please see Paul Dix’s blog post on InfluxDB Clustering, High-Availability, and Monetization. Please note that the 0.11 version of clustering is still considered experimental, and there are still quite a few rough edges.
Consensus nodes
Consensus nodes do not require significant system resources and can run on a very lightweight server.
Data or Hybrid nodes
Data nodes and Hybrid nodes have the following minimum hardware requirements:
- CPU: 2
- RAM: 4 GB
- IOPS: 1000+
For better performance, we recommend having 8 GB RAM and 4 CPUs or more.
When running a cluster every member should have at least two cores.
How should I configure my hardware differently from a single-node instance?
Place the hh directory on a separate storage device from the wal and data directories. This significantly reduces disk contention when the cluster is under heavy write load. For more information on setting up a cluster, see Cluster Setup.