This is archived documentation for InfluxData product versions that are no longer maintained. For newer documentation, see the latest InfluxData documentation.
This page addresses frequent sources of confusion and places where InfluxDB behaves in an unexpected way relative to other database systems. Where applicable, it links to outstanding issues on GitHub.
Querying data
- Getting unexpected results with
GROUP BY time() - Understanding the time intervals returned from
GROUP BY time()queries - Querying after
now() - Querying outside the min/max time range
- Querying a time range that spans epoch 0
- Querying with booleans
- Working with really big or really small integers
- Doing math on timestamps
- Getting an unexpected epoch 0 timestamp in query returns
- Getting large query returns in batches when using the HTTP API
- Getting the
expected identifiererror, unexpectedly - Identifying write precision from returned timestamps
- Single quoting and double quoting in queries
- Missing data after creating a new
DEFAULTretention policy
Writing data
- Writing integers
- Writing data with negative timestamps
- Writing duplicate points
- Getting an unexpected error when sending data over the HTTP API
- Writing more than one continuous query to a single series
- Words and characters to avoid
- Single quoting and double quoting when writing data
Administration
- Single quoting the password string
- Escaping the single quote in a password
- Identifying your version of InfluxDB
- Data aren’t dropped after altering a retention policy
Querying data
Getting unexpected results with GROUP BY time()
A query that includes a GROUP BY time() clause can yield unexpected results:
- InfluxDB returns a single aggregated value with the timestamp
'1970-01-01T00:00:00Z'even though the data include more than one instance of the time interval specified intime() - InfluxDB returns
ERR: too many points in the group by interval. maybe you forgot to specify a where time clause?even though the query includes aWHEREtime clause.
Those returns typically proceed from the combination of the following two features of InfluxDB:
- By default, InfluxDB uses epoch 0 (
1970-01-01T00:00:00Z) as the lower bound andnow()as the upper bound in queries. - A query that includes
GROUP BY time()must cover fewer than 100,000 instances of the supplied time interval
If your WHERE time clause is simply WHERE time < now() InfluxDB queries the data back to epoch 0 - that behavior often causes the query to breach the 100,000 instances rule and InfluxDB returns a confusing error or result.
Avoid perplexing GROUP BY time() returns by specifying a valid time interval in the WHERE clause.
Understanding the time intervals returned from GROUP BY time() queries
With some GROUP BY time() queries, the returned time intervals may not reflect the time range specified in the WHERE clause.
In the example below the first timestamp in the results occurs before the lower bound of the query:
Query with a two day GROUP BY time() interval:
> SELECT count(water_level) FROM h2o_feet WHERE time >= ‘2015-08-20T00:00:00Z’ AND time <= ‘2015-08-24T00:00:00Z’ AND location = ‘santa_monica’ GROUP BY time(2d)
Results:
name: h2o_feet
--------------
time count
2015-08-19T00:00:00Z 240
2015-08-21T00:00:00Z 480
2015-08-23T00:00:00Z 241
InfluxDB queries the GROUP BY time() intervals that fall within the WHERE time clause.
GROUP BY time() intervals always fall on rounded calendar time boundaries.
Because they’re rounded time boundaries, the start and end timestamps may appear to include more data than those covered by the query’s WHERE time clause.
For the example above, InfluxDB works with two day intervals based on round number calendar days. The rounded two day buckets in August are as follows (explanation continues below):
August 1st-2nd
August 3rd-4th
[...]
August 19th-20th
August 21st-22nd
August 23rd-24th
[...]
Because InfluxDB automatically groups together August 19th and August 20th, August 19th is the first timestamp to appear in the results despite not being within the query’s time range.
The number in the count column, however, only includes data that occur on or after August 20th as that is the time range specified by the query’s WHERE clause.
See GitHub Issue #1837 for more context on the future development of GROUP BY time() windows.
Querying after now()
By default, InfluxDB uses now() (the current nanosecond timestamp of the node that is processing the query) as the upper bound in queries.
You must provide explicit directions in the WHERE clause to query points that occur after now().
The first query below asks InfluxDB to return everything from hillvalley that occurs between epoch 0 (1970-01-01T00:00:00Z) and now().
The second query asks InfluxDB to return everything from hillvalley that occurs between epoch 0 and 1,000 days from now().
SELECT * FROM hillvalleySELECT * FROM hillvalley WHERE time < now() + 1000d
Querying outside the min/max time range
Queries with a time range that exceeds the minimum or maximum timestamps valid for InfluxDB currently return no results, rather than an error message.
Smallest valid timestamp: -9023372036854775808 (approximately 1684-01-22T14:50:02Z)
Largest valid timestamp: 9023372036854775807 (approximately 2255-12-09T23:13:56Z)
Querying a time range that spans epoch 0
Currently, InfluxDB can return results for queries that cover either the time range before epoch 0 or the time range after epoch 0, not both. A query with a time range that spans epoch 0 returns partial results.
Querying with booleans
Acceptable boolean syntax differs for data writes and data queries.
| Boolean syntax | Writes | Queries |
|---|---|---|
t,f | ✔️ | ❌ |
T,F | ✔️ | ❌ |
true,false | ✔️ | ✔️ |
True,False | ✔️ | ✔️ |
TRUE,FALSE | ✔️ | ✔️ |
For example, SELECT * FROM hamlet WHERE bool=True returns all points with bool set to TRUE, but SELECT * FROM hamlet WHERE bool=T returns all points withbool set to false.
Working with really big or really small integers
InfluxDB stores all integers as signed int64 data types.
The minimum and maximum valid values for int64 are -9023372036854775808 and 9023372036854775807.
See Go builtins for more information.
Values close to but within those limits may lead to unexpected results; some functions and operators convert the int64 data type to float64 during calculation which can cause overflow issues.
Doing math on timestamps
Currently, it is not possible to execute mathematical operators or functions against timestamp values in InfluxDB. All time calculations must be carried out by the client receiving the query results.
Getting an unexpected epoch 0 timestamp in query returns
In InfluxDB, epoch 0 (1970-01-01T00:00:00Z) is often used as a null timestamp equivalent.
If you request a query that has no timestamp to return, such as an aggregation function with an unbounded time range, InfluxDB returns epoch 0 as the timestamp.
Getting large query returns in batches when using the HTTP API
InfluxDB returns large query results in batches of 10,000 points unless you use the query string parameter chunk_size to explicitly set the batch size.
For example, get results in batches of 20,000 points with:
curl -G 'http://localhost:8086/query' --data-urlencode "db=deluge" --data-urlencode "chunk_size=20000" --data-urlencode "q=SELECT * FROM liters"
See GitHub Issue #3242 for more information on the challenges that this can cause, especially with Grafana visualization.
Getting the expected identifier error, unexpectedly
Receiving the error ERR: error parsing query: found [WORD], expected identifier[, string, number, bool] is often a gentle reminder that you forgot to include something in your query, as is the case in the following examples:
SELECT FROM logic WHERE rational = 5should beSELECT something FROM logic WHERE rational = 5SELECT * FROM WHERE rational = 5should beSELECT * FROM logic WHERE rational = 5
In other cases, your query seems complete but you receive the same error:
SELECT field FROM whySELECT * FROM why WHERE tag = '1'SELECT * FROM grant WHERE why = 9
In the last three queries, and in most unexpected expected identifier errors, at least one of the identifiers in the query is an InfluxQL keyword.
Identifiers are database names, retention policy names, user names, measurement names, tag keys, and field keys.
To successfully query data that use a keyword as an identifier enclose that identifier in double quotes, so the examples above become:
SELECT "field" FROM whySELECT * FROM why WHERE "tag" = '1'SELECT * FROM "grant" WHERE why = 9
While using double quotes is an acceptable workaround, we recommend that you avoid using InfluxQL keywords as identifiers for simplicity’s sake. The InfluxQL documentation has a comprehensive list of all InfluxQL keywords.
Identifying write precision from returned timestamps
InfluxDB stores all timestamps as nanosecond values regardless of the write precision supplied. It is important to note that when returning query results, the database silently drops trailing zeros from timestamps which obscures the initial write precision.
In the example below, the tags precision_supplied and timestamp_supplied show the time precision and timestamp that the user provided at the write.
Because InfluxDB silently drops trailing zeros on returned timestamps, the write precision is not recognizable in the returned timestamps.
name: trails
-------------
time value precision_supplied timestamp_supplied
1970-01-01T01:00:00Z 3 n 3600000000000
1970-01-01T01:00:00Z 5 h 1
1970-01-01T02:00:00Z 4 n 7200000000000
1970-01-01T02:00:00Z 6 h 2Single quoting and double quoting in queries
Single quote string values (for example, tag values) but do not single quote identifiers (database names, retention policy names, user names, measurement names, tag keys, and field keys).
Double quote identifiers if they start with a digit, contain characters other than [A-z,0-9,_], or if they are an InfluxQL keyword.
You can double quote identifiers even if they don’t fall into one of those categories but it isn’t necessary.
Yes: SELECT bikes_available FROM bikes WHERE station_id='9'
Yes: SELECT "bikes_available" FROM "bikes" WHERE "station_id"='9'
Yes: SELECT * from "cr@zy" where "p^e"='2'
No: SELECT 'bikes_available' FROM 'bikes' WHERE 'station_id'="9"
No: SELECT * from cr@zy where p^e='2'
See the Query Syntax page for more information.
Missing data after creating a new DEFAULT retention policy
When you create a new DEFAULT retention policy (RP) on a database, the data written to the old DEFAULT RP remain in the old RP.
Queries that do not specify an RP automatically query the new DEFAULT RP so the old data may appear to be missing.
To query the old data you must fully qualify the relevant data in the query.
Example:
All of the data in the measurement fleeting fall under the DEFAULT RP called one_hour:
> SELECT count(flounders) FROM fleeting
name: fleeting
--------------
time count
1970-01-01T00:00:00Z 8We create a new DEFAULT RP (two_hour) and perform the same query:
> SELECT count(flounders) FROM fleeting
>To query the old data, we must specify the old DEFAULT RP by fully qualifying fleeting:
> SELECT count(flounders) FROM fish.one_hour.fleeting
name: fleeting
--------------
time count
1970-01-01T00:00:00Z 8Writing data
Writing integers
Add a trailing i to the end of the field value when writing an integer.
If you do not provide the i, InfluxDB will treat the field value as a float.
Writes an integer: value=100i
Writes a float: value=100
Note: This syntax for writing integers is for versions 0.9.3+. Versions prior to 0.9.3 had a different syntax, see PR #3526.
Writing data with negative timestamps
There was a bug in the line protocol parser in versions 0.9.0 to 0.9.4 which treated negative timestamps as invalid syntax.
For example, INSERT waybackwhen past=1 -1 returned ERR: unable to parse 'waybackwhen past=1 -1': bad timestamp.
Starting with version 0.9.5 and later, the line protocol parser accepts negative timestamps.
Writing duplicate points
In InfluxDB 0.9 a point is uniquely identified by the measurement name, full [tag set]()(/influxdb/v0.9/concepts/glossary/#tag-set), and the nanosecond timestamp. If a point is submitted with an identical measurement, tag set, and timestamp it will silently overwrite the previous point. This is the intended behavior.
For example,cpu_load,hostname=server02,az=us_west value=24.5 1234567890000000 andcpu_load,hostname=server02,az=us_west value=5.24 1234567890000000 are identical points.
The last one written will overwrite the other.
In order to store both points, simply introduce an arbitrary new tag to enforce uniqueness.cpu_load,hostname=server02,az=us_west,uniq=1 value=24.5 1234567890000000 andcpu_load,hostname=server02,az=us_west,uniq=2 value=5.24 1234567890000000 are now unique points, and each will persist in the database.
You can also increment the timestamp by a nanosecond:cpu_load,hostname=server02,az=us_west,uniq=1 value=24.5 1234567890000000 andcpu_load,hostname=server02,az=us_west,uniq=2 value=5.24 1234567890000001 are now unique points, and each will persist in the database.
Note: The field set has nothing to do with the uniqueness of a point. These are still identical points and the last one written would be the only one to persist:
cpu_load,hostname=server02,az=us_west value=24.5 1234567890000000andcpu_load,hostname=server02,az=us_west loadavg=12.2 1234567890000000are still identical points. The last one written will overwrite the other.
Getting an unexpected error when sending data over the HTTP API
First, double check your line protocol syntax.
Second, if you continue to receive errors along the lines of bad timestamp or unable to parse, verify that your newline character is line feed (\n, which is ASCII 0x0A).
InfluxDB’s line protocol relies on \n to indicate the end of a line and the beginning of a new line; files or data that use a newline character other than \n will encounter parsing issues.
Convert the newline character and try sending the data again.
Note: If you generated your data file on a Windows machine, Windows uses carriage return and line feed (
\r\n) as the newline character.
Writing more than one continuous query to a single series
Use a single continuous query to write several statistics to the same measurement and tag set.
For example, tell InfluxDB to write to the aggregated_stats measurement the MEAN and MIN of the value field grouped by five-minute intervals and grouped by the cpu tag with:
CREATE CONTINUOUS QUERY mean_min_value ON telegraf BEGIN SELECT MEAN(value) AS mean, MIN(value) AS min INTO aggregated_stats FROM cpu_idle GROUP BY time(5m),cpu ENDIf you create two separate continuous queries (one for calculating the MEAN and one for calculating the MIN), the aggregated_stats measurement will appear to be missing data.
Separate continuous queries run at slightly different times and InfluxDB defines a unique point by its measurement, tag set, and timestamp (notice that field is missing from that list).
So if two continuous queries write to different fields but also write to the same measurement and tag set, only one of the two fields will ever have data; the last continuous query to run will overwrite the results that were written by the first continuous query with the same timestamp.
For more on continuous queries, see Continuous Queries.
Words and characters to avoid
If you use any of the InfluxQL keywords as an identifier you will need to double quote that identifier in every query. This can lead to non-intuitive errors. Identifiers are database names, retention policy names, user names, measurement names, tag keys, and field keys.
To keep regular expressions and quoting simple, avoid using the following characters in identifiers:
\ backslash^ circumflex accent$ dollar sign' single quotation mark" double quotation mark, comma
Single quoting and double quoting when writing data
- Avoid single quoting and double quoting identifiers when writing data via the line protocol; see the examples below for how writing identifiers with quotes can complicate queries.
Identifiers are database names, retention policy names, user names, measurement names, tag keys, and field keys.
Write with a double-quoted measurement:INSERT "bikes" bikes_available=3
Applicable query:SELECT * FROM "\"bikes\""
Write with a single-quoted measurement:INSERT 'bikes' bikes_available=3
Applicable query:SELECT * FROM "\'bikes\'"
Write with an unquoted measurement:INSERT bikes bikes_available=3
Applicable query:SELECT * FROM bikes - Double quote field values that are strings.
Write:INSERT bikes happiness="level 2"
Applicable query:SELECT * FROM bikes WHERE happiness='level 2' - Special characters should be escaped with a backslash and not placed in quotes.
Write:INSERT wacky va\"ue=4
Applicable query:SELECT "va\"ue" FROM wacky
See the Line Protocol Syntax page for more information.
Administration
Single quoting the password string
The CREATE USER <user> WITH PASSWORD '<password>' query requires single quotation marks around the password string.
Do not include the single quotes when authenticating requests.
Escaping the single quote in a password
For passwords that include a single quote, escape the single quote with a backslash both when creating the password and when authenticating requests.
Identifying your version of InfluxDB
There a number of ways to identify the version of InfluxDB that you’re using:
- Check the return when you
curlthe/pingendpoint. For example, if you’re using 0.9.3curl -i 'http://localhost:8086/ping'returns:
HTTP/1.1 204 No ContentRequest-Id: b7d7e0d6-5339-11e5-80bb-000000000000
✨X-Influxdb-Version: 0.9.3✨
Date: Fri, 04 Sep 2015 19:18:26 GMT
- Check the text that appears when you launch the CLI:
Connected to http://localhost:8086 ✨version 0.9.3✨InfluxDB shell 0.9.3
- Check the HTTP response in your logs:
[http] 2015/09/04 12:29:07 ::1 - - [04/Sep/2015:12:29:06 -0700] GET /query?db=&q=create+database+there_you_go HTTP/1.1 200 40 - ✨InfluxDBShell/0.9.3✨ 357970a0-533b-11e5-8001-000000000000 6.07408ms
Data aren’t dropped after altering a retention policy
After shortening the DURATION of a retention policy (RP), you may notice that InfluxDB keeps some data that are older than the DURATION of the modified RP.
This behavior is a result of the relationship between the time interval covered by a shard group and the DURATION of a retention policy.
InfluxDB stores data in shard groups.
A single shard group covers a specific time interval; InfluxDB determines that time interval by looking at the DURATION of the relevant RP.
The table below outlines the relationship between the DURATION of an RP and the time interval of a shard group:
| RP duration | Shard group interval |
|---|---|
| < 2 days | 1 hour |
| >= 2 days and <= 6 months | 1 day |
| > 6 months | 7 days |
If you shorten the DURATION of an RP and the shard group interval also shrinks, InfluxDB may be forced to keep data that are older than the new DURATION.
This happens because InfluxDB cannot divide the old, longer shard group into new, shorter shard groups; it must keep all of the data in the longer shard group even if only a small part of those data overlaps with the new DURATION.
Example: Moving from an infinite RP to a three day RP
Figure 1 shows the shard groups for our example database (example_db) after 11 days.
The database uses the automatically generated default retention policy with an infinite (INF) DURATION so each shard group interval is seven days.
On day 11, InfluxDB is no longer writing to Shard Group 1 and Shard Group 2 has four days worth of data:
Figure 1
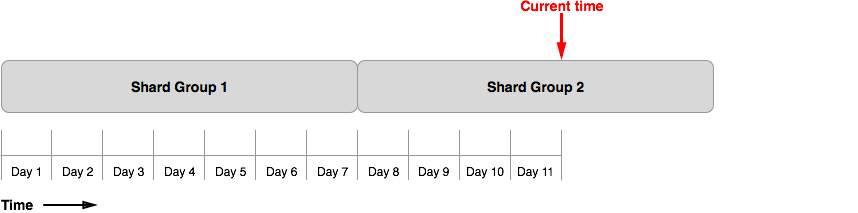
On day 11, we notice that example_db is accruing data too fast; we want to delete, and keep deleting, all data older than three days.
We do this by altering the retention policy:
> ALTER RETENTION POLICY default ON example_db DURATION 3d
At the next retention policy enforcement check, InfluxDB immediately drops Shard Group 1 because all of its data is older than 3 days.
InfluxDB does not drop Shard Group 2.
This is because InfluxDB cannot divide existing shard groups and some data in Shard Group 2 still fall within the new three day retention policy.
Figure 2 shows the shard groups for example_db five days after the retention policy change.
Notice that the new shard groups span one day intervals.
All of the data in Shard Group 2 remain in the database because the shard group still has data within the retention policy’s three day DURATION:
Figure 2
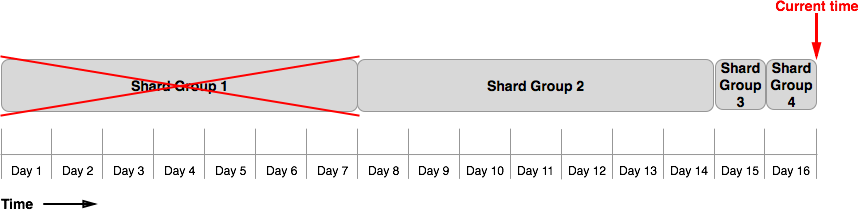
After day 17, all data within the past 3 days will be in one day shard groups.
InfluxDB will then be able to drop Shard Group 2 and example_db will have only 3 days worth of data.
Note: The time it takes for InfluxDB to adjust to the new retention policy may be longer depending on your shard precreation configuration setting. See Database Configuration for more on that setting.