This is archived documentation for InfluxData product versions that are no longer maintained. For newer documentation, see the latest InfluxData documentation.
Use InfluxQL functions to aggregate, select, transform, and predict data.
Useful InfluxQL for functions:
- Include multiple functions in a single query
- Change the value reported for intervals with no data with
fill() - Rename the output column’s title with
AS
The examples below query data using InfluxDB’s Command Line Interface (CLI). See the Querying Data guide for how to query data directly using the HTTP API.
Sample data
The examples in this document use the same sample data as the Data Exploration page. The data is described and available for download on the Sample Data page.
Aggregations
COUNT()
Returns the number of non-null values in a single field.
COUNT() accepts all field types; an * indicates all fields in the measurement.
SELECT COUNT(<field_key>) FROM <measurement_name> [WHERE <stuff>] [GROUP BY <stuff>]
Examples:
Count the number of non-null field values in the
water_levelfield:> SELECT COUNT("water_level") FROM "h2o_feet" name: h2o_feet -------------- time count 1970-01-01T00:00:00Z 15258
Note: Aggregation functions return epoch 0 (
1970-01-01T00:00:00Z) as the timestamp unless you specify a lower bound on the time range. Then they return the lower bound as the timestamp.
Count the number of non-null field values in the
water_levelfield at four-day intervals:> SELECT COUNT("water_level") FROM "h2o_feet" WHERE time >= '2015-08-18T00:00:00Z' AND time < '2015-09-18T17:00:00Z' GROUP BY time(4d) name: h2o_feet -------------- time count 2015-08-17T00:00:00Z 1440 2015-08-21T00:00:00Z 1920 2015-08-25T00:00:00Z 1920 2015-08-29T00:00:00Z 1920 2015-09-02T00:00:00Z 1915 2015-09-06T00:00:00Z 1920 2015-09-10T00:00:00Z 1920 2015-09-14T00:00:00Z 1920 2015-09-18T00:00:00Z 335Count the number of non-null field values for all fields (
level descriptionandwater_level) in the measurementh2o_feet:> SELECT COUNT(*) FROM "h2o_feet" name: h2o_feet -------------- time count_level description count_water_level 1970-01-01T00:00:00Z 15258 15258
COUNT()and controlling the values reported for intervals with no data
Other InfluxQL functions reportnullvalues for intervals with no data, and appendingfill(<stuff>)to queries with those functions replacesnullvalues in the output with<stuff>.COUNT(), however, reports0s for intervals with no data, so appendingfill(<stuff>)to queries withCOUNT()replaces0s in the output with<stuff>.Example: Use
fill(none)to suppress intervals with0data
COUNT()withoutfill(none):> SELECT COUNT("water_level") FROM "h2o_feet" WHERE "location" = 'santa_monica' AND time >= '2015-09-18T21:41:00Z' AND time <= '2015-09-18T22:41:00Z' GROUP BY time(30m) name: h2o_feet -------------- time count 2015-09-18T21:30:00Z 1 2015-09-18T22:00:00Z 0 2015-09-18T22:30:00Z 0
COUNT()withfill(none):> SELECT COUNT("water_level") FROM "h2o_feet" WHERE "location" = 'santa_monica' AND time >= '2015-09-18T21:41:00Z' AND time <= '2015-09-18T22:41:00Z' GROUP BY time(30m) fill(none) name: h2o_feet -------------- time count 2015-09-18T21:30:00Z 1For a more general discussion of
fill(), see Data Exploration.
DISTINCT()
Returns the unique values of a single field.
DISTINCT()) accepts all field types; an * indicates all fields in the measurement.
SELECT DISTINCT(<field_key>) FROM <measurement_name> [WHERE <stuff>] [GROUP BY <stuff>]
Examples:
Select the unique field values in the
level descriptionfield:> SELECT DISTINCT("level description") FROM "h2o_feet" name: h2o_feet -------------- time distinct 1970-01-01T00:00:00Z between 6 and 9 feet 1970-01-01T00:00:00Z below 3 feet 1970-01-01T00:00:00Z between 3 and 6 feet 1970-01-01T00:00:00Z at or greater than 9 feet
The response shows that level description has four distinct field values.
The timestamp reflects the first time the field value appears in the data.
Note: Aggregation functions return epoch 0 (
1970-01-01T00:00:00Z) as the timestamp unless you specify a lower bound on the time range. Then they return the lower bound as the timestamp.
Select the unique field values in the
level descriptionfield grouped by thelocationtag:> SELECT DISTINCT("level description") FROM "h2o_feet" GROUP BY "location" name: h2o_feet tags: location=coyote_creek time distinct ---- -------- 1970-01-01T00:00:00Z between 6 and 9 feet 1970-01-01T00:00:00Z between 3 and 6 feet 1970-01-01T00:00:00Z below 3 feet 1970-01-01T00:00:00Z at or greater than 9 feet name: h2o_feet tags: location=santa_monica time distinct ---- -------- 1970-01-01T00:00:00Z below 3 feet 1970-01-01T00:00:00Z between 3 and 6 feet 1970-01-01T00:00:00Z between 6 and 9 feetNest
DISTINCT()inCOUNT()to get the number of unique field values inlevel descriptiongrouped by thelocationtag:> SELECT COUNT(DISTINCT("level description")) FROM "h2o_feet" GROUP BY "location" name: h2o_feet tags: location = coyote_creek time count ---- ----- 1970-01-01T00:00:00Z 4 name: h2o_feet tags: location = santa_monica time count ---- ----- 1970-01-01T00:00:00Z 3Select the distinct field values for all fields (
level descriptionandwater_level) in the measurementh2o_feet:> SELECT DISTINCT(*) FROM "h2o_feet" LIMIT 5 name: h2o_feet -------------- time distinct_level description distinct_water_level 1970-01-01T00:00:00Z below 3 feet 2.064 1970-01-01T00:00:00Z between 6 and 9 feet 8.12 1970-01-01T00:00:00Z 2.116 1970-01-01T00:00:00Z 8.005 1970-01-01T00:00:00Z 2.028
INTEGRAL()
INTEGRAL() is not yet functional.
See GitHub Issue #5930 for more information.
MEAN()
Returns the arithmetic mean (average) for the values in a single field.
The field type must be int64 or float64; an * indicates all int64 or float64
fields in the measurement.
SELECT MEAN(<field_key>) FROM <measurement_name> [WHERE <stuff>] [GROUP BY <stuff>]
Examples:
Calculate the average value of the
water_levelfield:> SELECT MEAN("water_level") FROM "h2o_feet" name: h2o_feet -------------- time mean 1970-01-01T00:00:00Z 4.286791371454075
Notes:
- Aggregation functions return epoch 0 (
1970-01-01T00:00:00Z) as the timestamp unless you specify a lower bound on the time range. Then they return the lower bound as the timestamp.- Executing
mean()on the same set of float64 points may yield slightly different results. InfluxDB does not sort points before it applies the function which results in those small discrepancies.
Calculate the average value in the field
water_levelat four-day intervals:> SELECT MEAN("water_level") FROM "h2o_feet" WHERE time >= '2015-08-18T00:00:00Z' AND time < '2015-09-18T17:00:00Z' GROUP BY time(4d) name: h2o_feet -------------- time mean 2015-08-17T00:00:00Z 4.322029861111125 2015-08-21T00:00:00Z 4.251395512375667 2015-08-25T00:00:00Z 4.285036458333324 2015-08-29T00:00:00Z 4.469495801899061 2015-09-02T00:00:00Z 4.382785378590083 2015-09-06T00:00:00Z 4.28849666349042 2015-09-10T00:00:00Z 4.658127604166656 2015-09-14T00:00:00Z 4.763504687500006 2015-09-18T00:00:00Z 4.232829850746268Calculate the average value for all integer or float fields (in this case, just
water_level) in the measurementh2o_feet:> SELECT MEAN(*) FROM "h2o_feet" name: h2o_feet -------------- time mean_water_level 1970-01-01T00:00:00Z 4.44210702582251
MEDIAN()
Returns the middle value from the sorted values in a single field.
The field values must be of type int64 or float64; an * indicates all int64 or float64
fields in the measurement.
SELECT MEDIAN(<field_key>) FROM <measurement_name> [WHERE <stuff>] [GROUP BY <stuff>]
Note:
MEDIAN()is nearly equivalent toPERCENTILE(field_key, 50), exceptMEDIAN()returns the average of the two middle values if the field contains an even number of points.
Examples:
Select the median value in the field
water_level:> SELECT MEDIAN("water_level") FROM "h2o_feet" name: h2o_feet -------------- time median 1970-01-01T00:00:00Z 4.124
Note: Aggregation functions return epoch 0 (
1970-01-01T00:00:00Z) as the timestamp unless you specify a lower bound on the time range. Then they return the lower bound as the timestamp.
Select the median value of
water_levelbetween August 18, 2015 at 00:00:00 and August 18, 2015 at 00:30:00 grouped by thelocationtag:> SELECT MEDIAN("water_level") FROM "h2o_feet" WHERE time >= '2015-08-18T00:00:00Z' AND time < '2015-08-18T00:36:00Z' GROUP BY "location" name: h2o_feet tags: location = coyote_creek time median ---- ------ 2015-08-18T00:00:00Z 7.8245 name: h2o_feet tags: location = santa_monica time median ---- ------ 2015-08-18T00:00:00Z 2.0575Calculate the median value for all integer or float fields (in this case, just
water_level) in the measurementh2o_feet:> SELECT MEDIAN(*) FROM "h2o_feet" name: h2o_feet -------------- time median_water_level 1970-01-01T00:00:00Z 4.124
MODE()
Returns the most frequent value in a single field.
SELECT MODE(<field_key>) FROM <measurement_name> [WHERE <stuff>] [GROUP BY <stuff>]
Note:
MODE()will return the earliest metric value in case of a tie between two or more value for maximum occurrences
Examples:
Select the mode value in the field
water_level:> SELECT MODE("water_level") FROM "h2o_feet"
CLI response:
name: h2o_feet
--------------
time mode
1970-01-01T00:00:00Z 4
Note: Aggregation functions return epoch 0 (
1970-01-01T00:00:00Z) as the timestamp unless you specify a lower bound on the time range. Then they return the lower bound as the timestamp.
Select the mode value of
water_levelbetween August 18, 2015 at 00:00:00 and August 18, 2015 at 00:30:00 grouped by thelocationtag:> SELECT MODE("water_level") FROM "h2o_feet" WHERE time >= '2015-08-18T00:00:00Z' AND time < '2015-08-18T00:36:00Z' GROUP BY "location"
CLI response:
name: h2o_feet
tags: location = coyote_creek
time mode
---- ------
2015-08-18T00:00:00Z 7
name: h2o_feet
tags: location = santa_monica
time mode
---- ------
2015-08-18T00:00:00Z 2
SPREAD()
Returns the difference between the minimum and maximum values of a field.
The field must be of type int64 or float64; an * indicates all int64 or float64
fields in the measurement.
SELECT SPREAD(<field_key>) FROM <measurement_name> [WHERE <stuff>] [GROUP BY <stuff>]
Examples:
Calculate the difference between the minimum and maximum values across all values in the
water_levelfield:> SELECT SPREAD("water_level") FROM "h2o_feet" name: h2o_feet -------------- time spread 1970-01-01T00:00:00Z 10.574
Notes:
- Aggregation functions return epoch 0 (
1970-01-01T00:00:00Z) as the timestamp unless you specify a lower bound on the time range. Then they return the lower bound as the timestamp.- Executing
spread()on the same set of float64 points may yield slightly different results. InfluxDB does not sort points before it applies the function which results in those small discrepancies.
Calculate the difference between the minimum and maximum values in the field
water_levelfor a specific tag and time range and at 30 minute intervals:> SELECT SPREAD("water_level") FROM "h2o_feet" WHERE "location" = 'santa_monica' AND time >= '2015-09-18T17:00:00Z' AND time < '2015-09-18T20:30:00Z' GROUP BY time(30m) name: h2o_feet -------------- time spread 2015-09-18T17:00:00Z 0.16699999999999982 2015-09-18T17:30:00Z 0.5469999999999997 2015-09-18T18:00:00Z 0.47499999999999964 2015-09-18T18:30:00Z 0.2560000000000002 2015-09-18T19:00:00Z 0.23899999999999988 2015-09-18T19:30:00Z 0.1609999999999996 2015-09-18T20:00:00Z 0.16800000000000015Calculate the difference between the minimum and maximum values for all integer or float fields (in this case, just
water_level) in the measurementh2o_feet:> SELECT SPREAD(*) FROM "h2o_feet" name: h2o_feet -------------- time spread_water_level 1970-01-01T00:00:00Z 10.574
SUM()
Returns the sum of the all values in a single field.
The field must be of type int64 or float64; an * indicates all int64 or float64
fields in the measurement.
SELECT SUM(<field_key>) FROM <measurement_name> [WHERE <stuff>] [GROUP BY <stuff>]
Examples:
Calculate the sum of the values in the
water_levelfield:> SELECT SUM("water_level") FROM "h2o_feet" name: h2o_feet -------------- time sum 1970-01-01T00:00:00Z 67777.66900000002
Notes:
- Aggregation functions return epoch 0 (
1970-01-01T00:00:00Z) as the timestamp unless you specify a lower bound on the time range. Then they return the lower bound as the timestamp.- Executing
sum()on the same set of float64 points may yield slightly different results. InfluxDB does not sort points before it applies the function which results in those small discrepancies.
Calculate the sum of the
water_levelfield grouped by five-day intervals:> SELECT SUM("water_level") FROM "h2o_feet" WHERE time >= '2015-08-18T00:00:00Z' AND time < '2015-09-18T17:00:00Z' GROUP BY time(5d) name: h2o_feet -------------- time sum 2015-08-18T00:00:00Z 10334.908999999983 2015-08-23T00:00:00Z 10113.356999999995 2015-08-28T00:00:00Z 10663.683000000006 2015-09-02T00:00:00Z 10451.321 2015-09-07T00:00:00Z 10871.817999999994 2015-09-12T00:00:00Z 11459.00099999999 2015-09-17T00:00:00Z 3627.762000000003Calculate the sum for all integer or float fields (in this case, just
water_level) in the measurementh2o_feet:> SELECT SUM(*) FROM "h2o_feet" name: h2o_feet -------------- time sum_water_level 1970-01-01T00:00:00Z 67777.66900000005
STDDEV()
Returns the standard deviation of the values in a single field. The field must be of type int64 or float64.
SELECT STDDEV(<field_key>) FROM <measurement_name> [WHERE <stuff>] [GROUP BY <stuff>]
Examples:
Calculate the standard deviation for the
water_levelfield in the measurementh2o_feet:> SELECT STDDEV("water_level") FROM "h2o_feet" name: h2o_feet -------------- time stddev 1970-01-01T00:00:00Z 2.279144584196145
Notes:
- Aggregation functions returns epoch 0 (
1970-01-01T00:00:00Z) as the timestamp unless you specify a lower bound on the time range. Then they return the lower bound as the timestamp.- Executing
stddev()on the same set of float64 points may yield slightly different results. InfluxDB does not sort points before it applies the function which results in those small discrepancies.
Calculate the standard deviation for the
water_levelfield between August 18, 2015 at midnight and September 18, 2015 at noon grouped at one week intervals and by thelocationtag:> SELECT STDDEV("water_level") FROM "h2o_feet" WHERE time >= '2015-08-18T00:00:00Z' and time < '2015-09-18T12:06:00Z' GROUP BY time(1w), "location" name: h2o_feet tags: location = coyote_creek time stddev ---- ------ 2015-08-13T00:00:00Z 2.2437263080193985 2015-08-20T00:00:00Z 2.121276150144719 2015-08-27T00:00:00Z 3.0416122170786215 2015-09-03T00:00:00Z 2.5348065025435207 2015-09-10T00:00:00Z 2.584003954882673 2015-09-17T00:00:00Z 2.2587514836274414 name: h2o_feet tags: location = santa_monica time stddev ---- ------ 2015-08-13T00:00:00Z 1.11156344587553 2015-08-20T00:00:00Z 1.0909849279082366 2015-08-27T00:00:00Z 1.9870116180096962 2015-09-03T00:00:00Z 1.3516778450902067 2015-09-10T00:00:00Z 1.4960573811500588 2015-09-17T00:00:00Z 1.075701669442093
Selectors
BOTTOM()
Returns the smallest N values in a single field.
The field type must be int64 or float64.
SELECT BOTTOM(<field_key>[,<tag_keys>],<N>)[,<tag_keys>] FROM <measurement_name> [WHERE <stuff>] [GROUP BY <stuff>]
Examples:
Select the smallest three values of
water_level:> SELECT BOTTOM("water_level",3) FROM "h2o_feet" name: h2o_feet -------------- time bottom 2015-08-29T14:30:00Z -0.61 2015-08-29T14:36:00Z -0.591 2015-08-30T15:18:00Z -0.594Select the smallest three values of
water_leveland include the relevantlocationtag in the output:> SELECT BOTTOM("water_level",3),"location" FROM "h2o_feet" name: h2o_feet -------------- time bottom location 2015-08-29T14:30:00Z -0.61 coyote_creek 2015-08-29T14:36:00Z -0.591 coyote_creek 2015-08-30T15:18:00Z -0.594 coyote_creekSelect the smallest value of
water_levelwithin each tag value oflocation:> SELECT BOTTOM("water_level","location",2) FROM "h2o_feet" name: h2o_feet -------------- time bottom location 2015-08-29T10:36:00Z -0.243 santa_monica 2015-08-29T14:30:00Z -0.61 coyote_creek
The output shows the bottom values of water_level for each tag value of location (santa_monica and coyote_creek).
Note: Queries with the syntax
SELECT BOTTOM(<field_key>,<tag_key>,<N>), where the tag hasXdistinct values, returnNorXfield values, whichever is smaller, and each returned point has a unique tag value. To demonstrate this behavior, see the results of the above example query whereNequals3andNequals1.
N=3SELECT BOTTOM("water_level","location",3) FROM "h2o_feet" name: h2o_feet -------------- time bottom location 2015-08-29T10:36:00Z -0.243 santa_monica 2015-08-29T14:30:00Z -0.61 coyote_creekInfluxDB returns two values instead of three because the
locationtag has only two values (santa_monicaandcoyote_creek).
N=1> SELECT BOTTOM("water_level","location",1) FROM "h2o_feet" name: h2o_feet -------------- time bottom location 2015-08-29T14:30:00Z -0.61 coyote_creekInfluxDB compares the bottom values of
water_levelwithin each tag value oflocationand returns the smaller value ofwater_level.
Select the smallest two values of
water_levelbetween August 18, 2015 at 4:00:00 and August 18, 2015 at 4:18:00 for every tag value oflocation:> SELECT BOTTOM("water_level",2) FROM "h2o_feet" WHERE time >= '2015-08-18T04:00:00Z' AND time < '2015-08-18T04:24:00Z' GROUP BY "location" name: h2o_feet tags: location=coyote_creek time bottom ---- ------ 2015-08-18T04:12:00Z 2.717 2015-08-18T04:18:00Z 2.625 name: h2o_feet tags: location=santa_monica time bottom ---- ------ 2015-08-18T04:00:00Z 3.911 2015-08-18T04:06:00Z 4.055Select the smallest two values of
water_levelbetween August 18, 2015 at 4:00:00 and August 18, 2015 at 4:18:00 insanta_monica:> SELECT BOTTOM("water_level",2) FROM "h2o_feet" WHERE time >= '2015-08-18T04:00:00Z' AND time < '2015-08-18T04:24:00Z' AND "location" = 'santa_monica' name: h2o_feet -------------- time bottom 2015-08-18T04:00:00Z 3.911 2015-08-18T04:06:00Z 4.055
Note that in the raw data, water_level equals 4.055 at 2015-08-18T04:06:00Z and at 2015-08-18T04:12:00Z.
In the case of a tie, InfluxDB returns the value with the earlier timestamp.
FIRST()
Returns the oldest value (determined by the timestamp) of a single field.
SELECT FIRST(<field_key>)[,<tag_key(s)>] FROM <measurement_name> [WHERE <stuff>] [GROUP BY <stuff>]
Examples:
Select the oldest value of the field
water_levelwhere thelocationissanta_monica:> SELECT FIRST("water_level") FROM "h2o_feet" WHERE "location" = 'santa_monica' name: h2o_feet -------------- time first 2015-08-18T00:00:00Z 2.064Select the oldest value of the field
water_levelbetween2015-08-18T00:42:00Zand2015-08-18T00:54:00Z, and output the relevantlocationtag:> SELECT FIRST("water_level"),"location" FROM "h2o_feet" WHERE time >= '2015-08-18T00:42:00Z' and time <= '2015-08-18T00:54:00Z' name: h2o_feet -------------- time first location 2015-08-18T00:42:00Z 7.234 coyote_creekSelect the oldest values of the field
water_levelgrouped by thelocationtag:> SELECT FIRST("water_level") FROM "h2o_feet" GROUP BY "location" name: h2o_feet tags: location = coyote_creek time first ---- ----- 2015-08-18T00:00:00Z 8.12 name: h2o_feet tags: location = santa_monica time first ---- ----- 2015-08-18T00:00:00Z 2.064
LAST()
Returns the newest value (determined by the timestamp) of a single field.
SELECT LAST(<field_key>)[,<tag_key(s)>] FROM <measurement_name> [WHERE <stuff>] [GROUP BY <stuff>]
Examples:
Select the newest value of the field
water_levelwhere thelocationissanta_monica:> SELECT LAST("water_level") FROM "h2o_feet" WHERE "location" = 'santa_monica' name: h2o_feet -------------- time last 2015-09-18T21:42:00Z 4.938Select the newest value of the field
water_levelbetween2015-08-18T00:42:00Zand2015-08-18T00:54:00Z, and output the relevantlocationtag:> SELECT LAST("water_level"),"location" FROM "h2o_feet" WHERE time >= '2015-08-18T00:42:00Z' and time <= '2015-08-18T00:54:00Z' name: h2o_feet -------------- time last location 2015-08-18T00:54:00Z 6.982 coyote_creekSelect the newest values of the field
water_levelgrouped by thelocationtag:> SELECT LAST("water_level") FROM "h2o_feet" GROUP BY "location" name: h2o_feet tags: location = coyote_creek time last ---- ---- 2015-09-18T16:24:00Z 3.235 name: h2o_feet tags: location = santa_monica time last ---- ---- 2015-09-18T21:42:00Z 4.938
Note:
LAST()does not return points that occur afternow()unless theWHEREclause specifies that time range. See Frequently Asked Questions for how to query afternow().
MAX()
Returns the highest value in a single field. The field must be an int64, float64, or boolean.
SELECT MAX(<field_key>)[,<tag_key(s)>] FROM <measurement_name> [WHERE <stuff>] [GROUP BY <stuff>]
Examples:
Select the maximum
water_levelin the measurementh2o_feet:> SELECT MAX("water_level") FROM "h2o_feet" name: h2o_feet -------------- time max 2015-08-29T07:24:00Z 9.964Select the maximum
water_levelin the measurementh2o_feetand output the relevantlocationtag:> SELECT MAX("water_level"),"location" FROM "h2o_feet" name: h2o_feet -------------- time max location 2015-08-29T07:24:00Z 9.964 coyote_creekSelect the maximum
water_levelin the measurementh2o_feetbetween August 18, 2015 at midnight and August 18, 2015 at 00:48 grouped at 12 minute intervals and by thelocationtag:> SELECT MAX("water_level") FROM "h2o_feet" WHERE time >= '2015-08-18T00:00:00Z' AND time < '2015-08-18T00:54:00Z' GROUP BY time(12m), "location" name: h2o_feet tags: location = coyote_creek time max ---- --- 2015-08-18T00:00:00Z 8.12 2015-08-18T00:12:00Z 7.887 2015-08-18T00:24:00Z 7.635 2015-08-18T00:36:00Z 7.372 2015-08-18T00:48:00Z 7.11 name: h2o_feet tags: location = santa_monica time max ---- --- 2015-08-18T00:00:00Z 2.116 2015-08-18T00:12:00Z 2.126 2015-08-18T00:24:00Z 2.051 2015-08-18T00:36:00Z 2.067 2015-08-18T00:48:00Z 1.991
MIN()
Returns the lowest value in a single field. The field must be an int64, float64, or boolean.
SELECT MIN(<field_key>)[,<tag_key(s)>] FROM <measurement_name> [WHERE <stuff>] [GROUP BY <stuff>]
Examples:
Select the minimum
water_levelin the measurementh2o_feet:> SELECT MIN("water_level") FROM "h2o_feet" name: h2o_feet -------------- time min 2015-08-29T14:30:00Z -0.61Select the minimum
water_levelin the measurementh2o_feetand output the relevantlocationtag:> SELECT MIN("water_level"),"location" FROM "h2o_feet" name: h2o_feet -------------- time min location 2015-08-29T14:30:00Z -0.61 coyote_creekSelect the minimum
water_levelin the measurementh2o_feetbetween August 18, 2015 at midnight and August 18, at 00:48 grouped at 12 minute intervals and by thelocationtag:> SELECT MIN("water_level") FROM "h2o_feet" WHERE time >= '2015-08-18T00:00:00Z' AND time < '2015-08-18T00:54:00Z' GROUP BY time(12m), "location" name: h2o_feet tags: location = coyote_creek time min ---- --- 2015-08-18T00:00:00Z 8.005 2015-08-18T00:12:00Z 7.762 2015-08-18T00:24:00Z 7.5 2015-08-18T00:36:00Z 7.234 2015-08-18T00:48:00Z 7.11 name: h2o_feet tags: location = santa_monica time min ---- --- 2015-08-18T00:00:00Z 2.064 2015-08-18T00:12:00Z 2.028 2015-08-18T00:24:00Z 2.041 2015-08-18T00:36:00Z 2.057 2015-08-18T00:48:00Z 1.991
PERCENTILE()
Returns the Nth percentile value for the sorted values of a single field.
The field must be of type int64 or float64.
The percentile N must be an integer or floating point number between 0 and 100, inclusive.
SELECT PERCENTILE(<field_key>, <N>)[,<tag_key(s)>] FROM <measurement_name> [WHERE <stuff>] [GROUP BY <stuff>]
Examples:
Calculate the fifth percentile of the field
water_levelwhere the taglocationequalscoyote_creek:> SELECT PERCENTILE("water_level",5) FROM "h2o_feet" WHERE "location" = 'coyote_creek' name: h2o_feet -------------- time percentile 2015-09-09T11:42:00Z 1.148
The value 1.148 is larger than 5% of the values in water_level where location equals coyote_creek.
Calculate the fifth percentile of the field
water_leveland output the relevantlocationtag:> SELECT PERCENTILE("water_level",5),"location" FROM "h2o_feet" name: h2o_feet -------------- time percentile location 2015-08-28T12:06:00Z 1.122 santa_monicaCalculate the 100th percentile of the field
water_levelgrouped by thelocationtag:> SELECT PERCENTILE("water_level", 100) FROM "h2o_feet" GROUP BY "location" name: h2o_feet tags: location = coyote_creek time percentile ---- ---------- 2015-08-29T07:24:00Z 9.964 name: h2o_feet tags: location = santa_monica time percentile ---- ---------- 2015-08-29T03:54:00Z 7.205
Notice that PERCENTILE(<field_key>,100) is equivalent to MAX(<field_key>).
Currently, PERCENTILE(<field_key>,0) is not equivalent to MIN(<field_key>).
See GitHub Issue #4418 for more information.
Note:
PERCENTILE(<field_key>, 50)is nearly equivalent toMEDIAN(), exceptMEDIAN()returns the average of the two middle values if the field contains an even number of points.
TOP()
Returns the largest N values in a single field.
The field type must be int64 or float64.
SELECT TOP(<field_key>[,<tag_keys>],<N>)[,<tag_keys>] FROM <measurement_name> [WHERE <stuff>] [GROUP BY <stuff>]
Examples:
Select the largest three values of
water_level:> SELECT TOP("water_level",3) FROM "h2o_feet" name: h2o_feet -------------- time top 2015-08-29T07:18:00Z 9.957 2015-08-29T07:24:00Z 9.964 2015-08-29T07:30:00Z 9.954Select the largest three values of
water_leveland include the relevantlocationtag in the output:> SELECT TOP("water_level",3),"location" FROM "h2o_feet" name: h2o_feet -------------- time top location 2015-08-29T07:18:00Z 9.957 coyote_creek 2015-08-29T07:24:00Z 9.964 coyote_creek 2015-08-29T07:30:00Z 9.954 coyote_creekSelect the largest value of
water_levelwithin each tag value oflocation:> SELECT TOP("water_level","location",2) FROM "h2o_feet" name: h2o_feet -------------- time top location 2015-08-29T03:54:00Z 7.205 santa_monica 2015-08-29T07:24:00Z 9.964 coyote_creek
The output shows the top values of water_level for each tag value of location (santa_monica and coyote_creek).
Note: Queries with the syntax
SELECT TOP(<field_key>,<tag_key>,<N>), where the tag hasXdistinct values, returnNorXfield values, whichever is smaller, and each returned point has a unique tag value. To demonstrate this behavior, see the results of the above example query whereNequals3andNequals1.
N=3> SELECT TOP("water_level","location",3) FROM "h2o_feet" name: h2o_feet -------------- time top location 2015-08-29T03:54:00Z 7.205 santa_monica 2015-08-29T07:24:00Z 9.964 coyote_creekInfluxDB returns two values instead of three because the
locationtag has only two values (santa_monicaandcoyote_creek).
N=1> SELECT TOP("water_level","location",1) FROM "h2o_feet" name: h2o_feet -------------- time top location 2015-08-29T07:24:00Z 9.964 coyote_creekInfluxDB compares the top values of
water_levelwithin each tag value oflocationand returns the larger value ofwater_level.
Select the largest two values of
water_levelbetween August 18, 2015 at 4:00:00 and August 18, 2015 at 4:18:00 for every tag value oflocation:> SELECT TOP("water_level",2) FROM "h2o_feet" WHERE time >= '2015-08-18T04:00:00Z' AND time < '2015-08-18T04:24:00Z' GROUP BY "location" name: h2o_feet tags: location=coyote_creek time top ---- --- 2015-08-18T04:00:00Z 2.943 2015-08-18T04:06:00Z 2.831 name: h2o_feet tags: location=santa_monica time top ---- --- 2015-08-18T04:06:00Z 4.055 2015-08-18T04:18:00Z 4.124Select the largest two values of
water_levelbetween August 18, 2015 at 4:00:00 and August 18, 2015 at 4:18:00 insanta_monica:> SELECT TOP("water_level",2) FROM "h2o_feet" WHERE time >= '2015-08-18T04:00:00Z' AND time < '2015-08-18T04:24:00Z' AND "location" = 'santa_monica' name: h2o_feet -------------- time top 2015-08-18T04:06:00Z 4.055 2015-08-18T04:18:00Z 4.124
Note that in the raw data, water_level equals 4.055 at 2015-08-18T04:06:00Z and at 2015-08-18T04:12:00Z.
In the case of a tie, InfluxDB returns the value with the earlier timestamp.
Transformations
CEILING()
CEILING() is not yet functional.
See GitHub Issue #5930 for more information.
DERIVATIVE()
Returns the rate of change for the values in a single field in a series.
InfluxDB calculates the difference between chronological field values and converts those results into the rate of change per unit.
The unit argument is optional and, if not specified, defaults to one second (1s).
The basic DERIVATIVE() query:
SELECT DERIVATIVE(<field_key>, [<unit>]) FROM <measurement_name> [WHERE <stuff>]
Valid time specifications for unit are:u microsecondss secondsm minutesh hoursd daysw weeks
DERIVATIVE() also works with a nested function coupled with a GROUP BY time() clause.
For queries that include those options, InfluxDB first performs the aggregation, selection, or transformation across the time interval specified in the GROUP BY time() clause.
It then calculates the difference between chronological field values and
converts those results into the rate of change per unit.
The unit argument is optional and, if not specified, defaults to the same
interval as the GROUP BY time() interval.
The DERIVATIVE() query with an aggregation function and GROUP BY time() clause:
SELECT DERIVATIVE(AGGREGATION_FUNCTION(<field_key>),[<unit>]) FROM <measurement_name> WHERE <stuff> GROUP BY time(<aggregation_interval>)
Examples:
The following examples work with the first six observations of the water_level field in the measurement h2o_feet with the tag set location = santa_monica:
name: h2o_feet
--------------
time water_level
2015-08-18T00:00:00Z 2.064
2015-08-18T00:06:00Z 2.116
2015-08-18T00:12:00Z 2.028
2015-08-18T00:18:00Z 2.126
2015-08-18T00:24:00Z 2.041
2015-08-18T00:30:00Z 2.051DERIVATIVE()with a single argument:
Calculate the rate of change per one second> SELECT DERIVATIVE("water_level") FROM "h2o_feet" WHERE "location" = 'santa_monica' LIMIT 5 name: h2o_feet -------------- time derivative 2015-08-18T00:06:00Z 0.00014444444444444457 2015-08-18T00:12:00Z -0.00024444444444444465 2015-08-18T00:18:00Z 0.0002722222222222218 2015-08-18T00:24:00Z -0.000236111111111111 2015-08-18T00:30:00Z 2.777777777777842e-05
Notice that the first field value (0.00014) in the derivative column is not 0.052 (the difference between the first two field values in the raw data: 2.116 - 2.604 = 0.052).
Because the query does not specify the unit option, InfluxDB automatically calculates the rate of change per one second, not the rate of change per six minutes.
The calculation of the first value in the derivative column looks like this:
(2.116 - 2.064) / (360s / 1s)
The numerator is the difference between chronological field values.
The denominator is the difference between the relevant timestamps in seconds (2015-08-18T00:06:00Z - 2015-08-18T00:00:00Z = 360s) divided by unit (1s).
This returns the rate of change per second from 2015-08-18T00:00:00Z to 2015-08-18T00:06:00Z.
DERIVATIVE()with two arguments:
Calculate the rate of change per six minutes> SELECT DERIVATIVE("water_level",6m) FROM "h2o_feet" WHERE "location" = 'santa_monica' LIMIT 5 name: h2o_feet -------------- time derivative 2015-08-18T00:06:00Z 0.052000000000000046 2015-08-18T00:12:00Z -0.08800000000000008 2015-08-18T00:18:00Z 0.09799999999999986 2015-08-18T00:24:00Z -0.08499999999999996 2015-08-18T00:30:00Z 0.010000000000000231
The calculation of the first value in the derivative column looks like this:
(2.116 - 2.064) / (6m / 6m)
The numerator is the difference between chronological field values.
The denominator is the difference between the relevant timestamps in minutes (2015-08-18T00:06:00Z - 2015-08-18T00:00:00Z = 6m) divided by unit (6m).
This returns the rate of change per six minutes from 2015-08-18T00:00:00Z to 2015-08-18T00:06:00Z.
DERIVATIVE()with two arguments:
Calculate the rate of change per 12 minutes> SELECT DERIVATIVE("water_level",12m) FROM "h2o_feet" WHERE "location" = 'santa_monica' LIMIT 5 name: h2o_feet -------------- time derivative 2015-08-18T00:06:00Z 0.10400000000000009 2015-08-18T00:12:00Z -0.17600000000000016 2015-08-18T00:18:00Z 0.19599999999999973 2015-08-18T00:24:00Z -0.16999999999999993 2015-08-18T00:30:00Z 0.020000000000000462
The calculation of the first value in the derivative column looks like this:
(2.116 - 2.064 / (6m / 12m)
The numerator is the difference between chronological field values.
The denominator is the difference between the relevant timestamps in minutes (2015-08-18T00:06:00Z - 2015-08-18T00:00:00Z = 6m) divided by unit (12m).
This returns the rate of change per 12 minutes from 2015-08-18T00:00:00Z to 2015-08-18T00:06:00Z.
Note: Specifying
12mas theunitdoes not mean that InfluxDB calculates the rate of change for every 12 minute interval of data. Instead, InfluxDB calculates the rate of change per 12 minutes for each interval of valid data.
DERIVATIVE()with one argument, a function, and aGROUP BY time()clause:
Select theMAX()value at 12 minute intervals and calculate the rate of change per 12 minutes> SELECT DERIVATIVE(MAX("water_level")) FROM "h2o_feet" WHERE "location" = 'santa_monica' AND time >= '2015-08-18T00:00:00Z' AND time < '2015-08-18T00:36:00Z' GROUP BY time(12m) name: h2o_feet -------------- time derivative 2015-08-18T00:12:00Z 0.009999999999999787 2015-08-18T00:24:00Z -0.07499999999999973
To get those results, InfluxDB first aggregates the data by calculating the MAX() water_level at the time interval specified in the GROUP BY time() clause (12m).
Those results look like this:
name: h2o_feet
--------------
time max
2015-08-18T00:00:00Z 2.116
2015-08-18T00:12:00Z 2.126
2015-08-18T00:24:00Z 2.051Second, InfluxDB calculates the rate of change per 12m (the same interval as the GROUP BY time() interval) to get the results in the derivative column above.
The calculation of the first value in the derivative column looks like this:
(2.126 - 2.116) / (12m / 12m)
The numerator is the difference between chronological field values.
The denominator is the difference between the relevant timestamps in minutes (2015-08-18T00:12:00Z - 2015-08-18T00:00:00Z = 12m) divided by unit (12m).
This returns rate of change per 12 minutes for the aggregated data from 2015-08-18T00:00:00Z to 2015-08-18T00:12:00Z.
DERIVATIVE()with two arguments, a function, and aGROUP BY time()clause:
Aggregate the data to 18 minute intervals and calculate the rate of change per six minutes> SELECT DERIVATIVE(SUM("water_level"),6m) FROM "h2o_feet" WHERE "location" = 'santa_monica' AND time >= '2015-08-18T00:00:00Z' AND time < '2015-08-18T00:36:00Z' GROUP BY time(18m) name: h2o_feet -------------- time derivative 2015-08-18T00:18:00Z 0.0033333333333332624
To get those results, InfluxDB first aggregates the data by calculating the SUM() of water_level at the time interval specified in the GROUP BY time() clause (18m).
The aggregated results look like this:
name: h2o_feet
--------------
time sum
2015-08-18T00:00:00Z 6.208
2015-08-18T00:18:00Z 6.218Second, InfluxDB calculates the rate of change per unit (6m) to get the results in the derivative column above.
The calculation of the first value in the derivative column looks like this:
(6.218 - 6.208) / (18m / 6m)
The numerator is the difference between chronological field values.
The denominator is the difference between the relevant timestamps in minutes (2015-08-18T00:18:00Z - 2015-08-18T00:00:00Z = 18m) divided by unit (6m).
This returns the rate of change per six minutes for the aggregated data from 2015-08-18T00:00:00Z to 2015-08-18T00:18:00Z.
DIFFERENCE()
Returns the difference between consecutive chronological values in a single field. The field type must be int64 or float64.
The basic DIFFERENCE() query:
SELECT DIFFERENCE(<field_key>) FROM <measurement_name> [WHERE <stuff>]
The DIFFERENCE() query with a nested function and a GROUP BY time() clause:
SELECT DIFFERENCE(<function>(<field_key>)) FROM <measurement_name> WHERE <stuff> GROUP BY time(<time_interval>)
Functions that work with DIFFERENCE() include
COUNT(),
MEAN(),
MEDIAN(),
SUM(),
FIRST(),
LAST(),
MIN(),
MAX(), and
PERCENTILE().
Examples:
The following examples focus on the field water_level in santa_monica
between 2015-08-18T00:00:00Z and 2015-08-18T00:36:00Z:
> SELECT "water_level" FROM "h2o_feet" WHERE "location"='santa_monica' AND time >= '2015-08-18T00:00:00Z' AND time <= '2015-08-18T00:36:00Z'
name: h2o_feet
--------------
time water_level
2015-08-18T00:00:00Z 2.064
2015-08-18T00:06:00Z 2.116
2015-08-18T00:12:00Z 2.028
2015-08-18T00:18:00Z 2.126
2015-08-18T00:24:00Z 2.041
2015-08-18T00:30:00Z 2.051
2015-08-18T00:36:00Z 2.067
Calculate the difference between
water_levelvalues:> SELECT DIFFERENCE("water_level") FROM "h2o_feet" WHERE "location"='santa_monica' AND time >= '2015-08-18T00:00:00Z' AND time <= '2015-08-18T00:36:00Z' name: h2o_feet -------------- time difference 2015-08-18T00:06:00Z 0.052000000000000046 2015-08-18T00:12:00Z -0.08800000000000008 2015-08-18T00:18:00Z 0.09799999999999986 2015-08-18T00:24:00Z -0.08499999999999996 2015-08-18T00:30:00Z 0.010000000000000231 2015-08-18T00:36:00Z 0.016000000000000014
The first value in the difference column is 2.116 - 2.064, and the second
value in the difference column is 2.028 - 2.116.
Please note that the extra decimal places are the result of floating point
inaccuracies.
Select the minimum
water_levelvalues at 12 minute intervals and calculate the difference between those values:> SELECT DIFFERENCE(MIN("water_level")) FROM "h2o_feet" WHERE "location"='santa_monica' AND time >= '2015-08-18T00:00:00Z' AND time <= '2015-08-18T00:36:00Z' GROUP BY time(12m) name: h2o_feet -------------- time difference 2015-08-18T00:12:00Z -0.03600000000000003 2015-08-18T00:24:00Z 0.0129999999999999 2015-08-18T00:36:00Z 0.026000000000000245
To get the values in the difference column, InfluxDB first selects the MIN()
values at 12 minute intervals:
> SELECT MIN("water_level") FROM "h2o_feet" WHERE "location"='santa_monica' AND time >= '2015-08-18T00:00:00Z' AND time <= '2015-08-18T00:36:00Z' GROUP BY time(12m)
name: h2o_feet
--------------
time min
2015-08-18T00:00:00Z 2.064
2015-08-18T00:12:00Z 2.028
2015-08-18T00:24:00Z 2.041
2015-08-18T00:36:00Z 2.067
It then uses those values to calculate the difference between chronological
values; the first value in the difference column is 2.028 - 2.064.
ELAPSED()
Returns the difference between subsequent timestamps in a single
field.
The unit argument is an optional
duration literal
and, if not specified, defaults to one nanosecond.
SELECT ELAPSED(<field_key>, <unit>) FROM <measurement_name> [WHERE <stuff>]
Examples:
Calculate the difference (in nanoseconds) between the timestamps in the field
h2o_feet:> SELECT ELAPSED("water_level") FROM "h2o_feet" WHERE "location" = 'santa_monica' AND time >= '2015-08-18T00:00:00Z' AND time <= '2015-08-18T00:24:00Z' name: h2o_feet -------------- time elapsed 2015-08-18T00:06:00Z 360000000000 2015-08-18T00:12:00Z 360000000000 2015-08-18T00:18:00Z 360000000000 2015-08-18T00:24:00Z 360000000000Calculate the number of one minute intervals between the timestamps in the field
h2o_feet:> SELECT ELAPSED("water_level",1m) FROM "h2o_feet" WHERE "location" = 'santa_monica' AND time >= '2015-08-18T00:00:00Z' AND time <= '2015-08-18T00:24:00Z' name: h2o_feet -------------- time elapsed 2015-08-18T00:06:00Z 6 2015-08-18T00:12:00Z 6 2015-08-18T00:18:00Z 6 2015-08-18T00:24:00Z 6
Note: InfluxDB returns
0ifunitis greater than the difference between the timestamps. For example, the timestamps inh2o_feetoccur at six minute intervals. If the query asks for the number of one hour intervals between the timestamps, InfluxDB returns0:> SELECT ELAPSED("water_level",1h) FROM "h2o_feet" WHERE "location" = 'santa_monica' AND time >= '2015-08-18T00:00:00Z' AND time <= '2015-08-18T00:24:00Z' name: h2o_feet -------------- time elapsed 2015-08-18T00:06:00Z 0 2015-08-18T00:12:00Z 0 2015-08-18T00:18:00Z 0 2015-08-18T00:24:00Z 0
FLOOR()
FLOOR() is not yet functional.
See GitHub Issue #5930 for more information.
HISTOGRAM()
HISTOGRAM() is not yet functional.
See GitHub Issue #5930 for more information.
MOVING_AVERAGE()
Returns the moving average across a window of consecutive chronological field values for a single field.
The field type must be int64 or float64.
The basic MOVING_AVERAGE() query:
SELECT MOVING_AVERAGE(<field_key>,<window>) FROM <measurement_name> [WHERE <stuff>]
The MOVING_AVERAGE() query with a nested function and a GROUP BY time() clause:
SELECT MOVING_AVERAGE(<function>(<field_key>),<window>) FROM <measurement_name> WHERE <stuff> GROUP BY time(<time_interval>)
Functions that work with MOVING_AVERAGE() include
COUNT(),
MEAN(),
MEDIAN(),
SUM(),
FIRST(),
LAST(),
MIN(),
MAX(), and
PERCENTILE().
Examples:
The following examples focus on the field water_level in santa_monica
between 2015-08-18T00:00:00Z and 2015-08-18T00:36:00Z:
> SELECT "water_level" FROM "h2o_feet" WHERE "location" = 'santa_monica' AND time >= '2015-08-18T00:00:00Z' AND time <= '2015-08-18T00:36:00Z'
name: h2o_feet
--------------
time water_level
2015-08-18T00:00:00Z 2.064
2015-08-18T00:06:00Z 2.116
2015-08-18T00:12:00Z 2.028
2015-08-18T00:18:00Z 2.126
2015-08-18T00:24:00Z 2.041
2015-08-18T00:30:00Z 2.051
2015-08-18T00:36:00Z 2.067
Calculate the moving average across every 2 field values:
> SELECT MOVING_AVERAGE("water_level",2) FROM "h2o_feet" WHERE "location" = 'santa_monica' AND time >= '2015-08-18T00:00:00Z' AND time <= '2015-08-18T00:36:00Z' name: h2o_feet -------------- time moving_average 2015-08-18T00:06:00Z 2.09 2015-08-18T00:12:00Z 2.072 2015-08-18T00:18:00Z 2.077 2015-08-18T00:24:00Z 2.0835 2015-08-18T00:30:00Z 2.0460000000000003 2015-08-18T00:36:00Z 2.059
The first value in the moving_average column is the average of 2.064 and
2.116, the second value in the moving_average column is the average of
2.116 and 2.028.
Select the minimum
water_levelat 12 minute intervals and calculate the moving average across every 2 field values:> SELECT MOVING_AVERAGE(MIN("water_level"),2) FROM "h2o_feet" WHERE "location" = 'santa_monica' AND time >= '2015-08-18T00:00:00Z' AND time <= '2015-08-18T00:36:00Z' GROUP BY time(12m) name: h2o_feet -------------- time moving_average 2015-08-18T00:12:00Z 2.0460000000000003 2015-08-18T00:24:00Z 2.0345000000000004 2015-08-18T00:36:00Z 2.0540000000000003
To get those results, InfluxDB first selects the MIN() water_level for every
12 minute interval:
name: h2o_feet
--------------
time min
2015-08-18T00:00:00Z 2.064
2015-08-18T00:12:00Z 2.028
2015-08-18T00:24:00Z 2.041
2015-08-18T00:36:00Z 2.067
It then uses those values to calculate the moving average across every 2 field
values; the first result in the moving_average column the average of 2.064
and 2.028, and the second result is the average of 2.028 and 2.041.
NON_NEGATIVE_DERIVATIVE()
Returns the non-negative rate of change for the values in a single field in a series.
InfluxDB calculates the difference between chronological field values and converts those results into the rate of change per unit.
The unit argument is optional and, if not specified, defaults to one second (1s).
The basic NON_NEGATIVE_DERIVATIVE() query:
SELECT NON_NEGATIVE_DERIVATIVE(<field_key>, [<unit>]) FROM <measurement_name> [WHERE <stuff>]
Valid time specifications for unit are:u microsecondss secondsm minutesh hoursd daysw weeks
NON_NEGATIVE_DERIVATIVE() also works with a nested function coupled with a GROUP BY time() clause.
For queries that include those options, InfluxDB first performs the aggregation, selection, or transformation across the time interval specified in the GROUP BY time() clause.
It then calculates the difference between chronological field values and
converts those results into the rate of change per unit.
The unit argument is optional and, if not specified, defaults to the same
interval as the GROUP BY time() interval.
The NON_NEGATIVE_DERIVATIVE() query with an aggregation function and GROUP BY time() clause:
SELECT NON_NEGATIVE_DERIVATIVE(AGGREGATION_FUNCTION(<field_key>),[<unit>]) FROM <measurement_name> WHERE <stuff> GROUP BY time(<aggregation_interval>)
See DERIVATIVE() for example queries.
All query results are the same for DERIVATIVE() and NON_NEGATIVE_DERIVATIVE except that NON_NEGATIVE_DERIVATIVE() returns only the positive values.
Include multiple functions in a single query
Separate multiple functions in one query with a ,.
Calculate the minimum water_level and the maximum water_level with a single query:
> SELECT MIN("water_level"), MAX("water_level") FROM "h2o_feet"
name: h2o_feet
--------------
time min max
1970-01-01T00:00:00Z -0.61 9.964
Change the value reported for intervals with no data with fill()
By default, queries with an InfluxQL function report null values for intervals with no data.
Append fill() to the end of your query to alter that value.
For a complete discussion of fill(), see Data Exploration.
Note:
fill()works differently withCOUNT(). See the documentation onCOUNT()for a function-specific use offill().
Rename the output column’s title with AS
By default, queries that include a function output a column that has the same name as that function.
If you’d like a different column name change it with an AS clause.
Before:
> SELECT MEAN("water_level") FROM "h2o_feet"
name: h2o_feet
--------------
time mean
1970-01-01T00:00:00Z 4.442107025822521
After:
> SELECT MEAN("water_level") AS "dream_name" FROM "h2o_feet"
name: h2o_feet
--------------
time dream_name
1970-01-01T00:00:00Z 4.442107025822521
Predictors
HOLT_WINTERS()
Returns N number of predicted values for a single field using the Holt-Winters seasonal method. The seasonal adjustment of the predicted values is optional. The field must be of type int64 or float64.
Use HOLT_WINTERS() to:
- Predict when data values will cross a given threshold.
- Compare predicted values with actual values to detect anomalies in your data.
Returns only the predicted values:
SELECT HOLT_WINTERS(FUNCTION(<field_key>),<N>,<S>) FROM <measurement_name> WHERE <stuff> GROUP BY time(<interval>)[,<stuff>]
Returns the fitted values and the predicted values:
SELECT HOLT_WINTERS_WITH_FIT(FUNCTION(<field_key>),<N>,<S>) FROM <measurement_name> WHERE <stuff> GROUP BY time(<interval>)[,<stuff>]
Syntax explanation:
N is the number of predicted values.
Those values occur at the same interval as the GROUP BY time() interval.
If your GROUP BY time() interval is 6m and N is 3 you’ll
receive three predicted values that are each six minutes apart.
S is the seasonal pattern parameter.
The parameter delimits the length of a seasonal pattern according to the
GROUP BY time() interval.
If your GROUP BY time() interval is 2m and S is 3, then the
seasonal pattern occurs every six minutes, that is, every three data points.
If you do not want to seasonally adjust your predicted values, set S to 0
or 1.
Notice that HOLT_WINTERS() requires the use of another InfluxQL function and a
GROUP BY time() clause.
That ensures that the function receives data that occur at consistent time
intervals.
Note: In some cases, users may receive fewer predicted points than requested by the
Nparameter. That behavior occurs when the math becomes unstable and cannot forecast more points. It implies that eitherHOLT_WINTERS()is not suited for the dataset or that the seasonal adjustment parameter is invalid and is confusing the algorithm.
Example:
In the following example we’ll apply HOLT_WINTERS() to the data in the
NOAA_water_database, and we’ll show the results using
Chronograf visualizations.
Raw Data
Our query focuses on the raw water_level data in santa_monica between August
22, 2015 at 22:12 and August 28, 2015 at 03:00:
SELECT "water_level" FROM "h2o_feet" WHERE "location"='santa_monica' AND time >= '2015-08-22 22:12:00' AND time <= '2015-08-28 03:00:00'
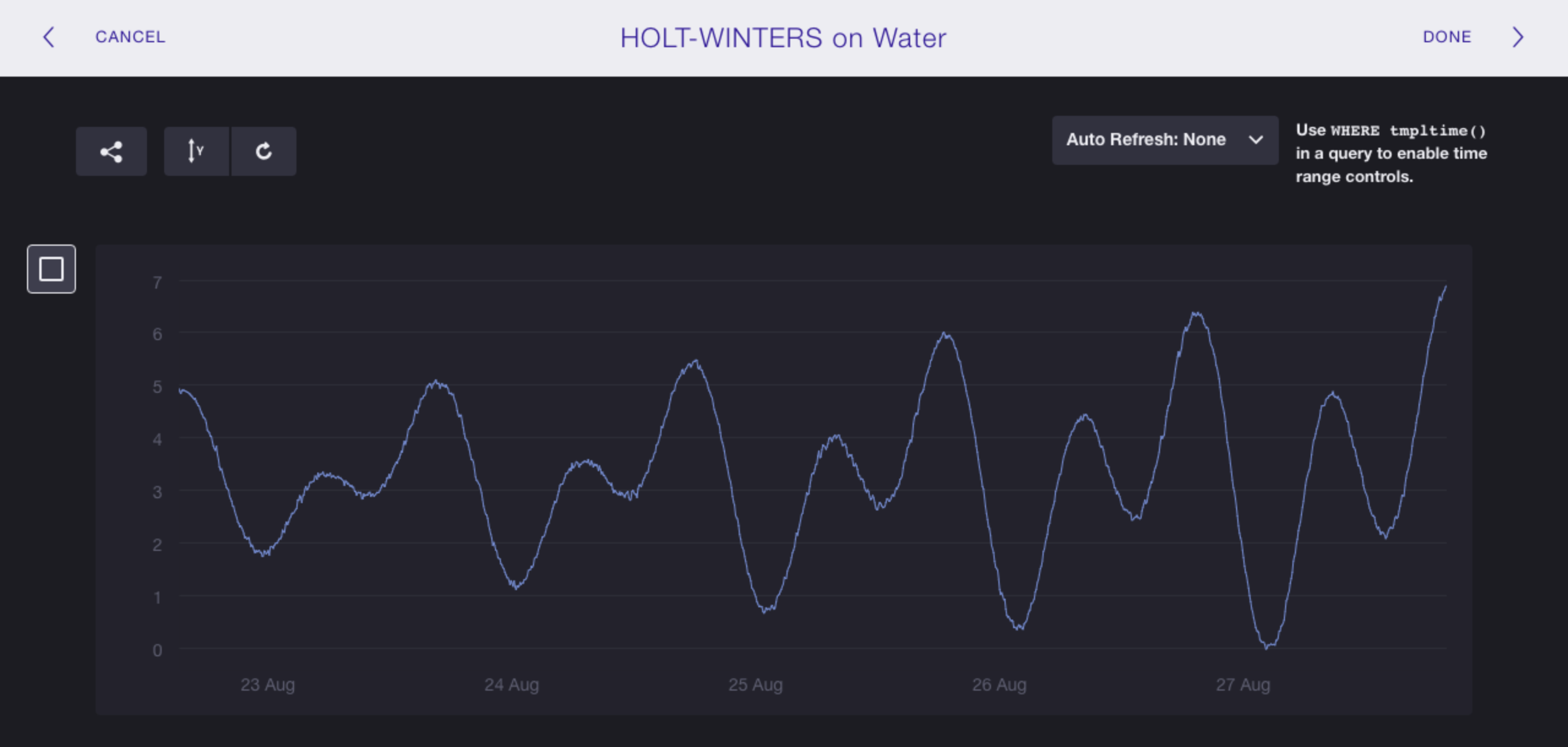
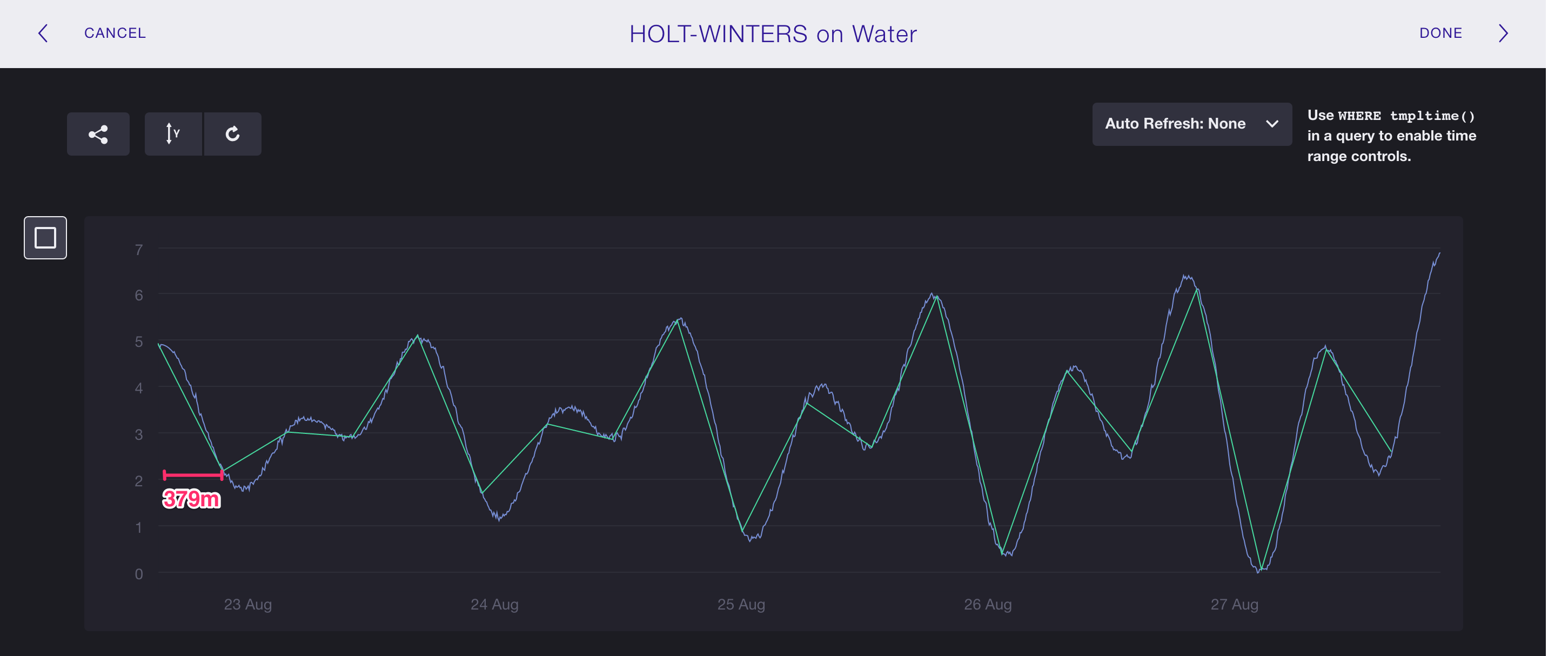
Step 1: Create a Query to Match the Trends of the Raw Data
We start by writing a GROUP BY time() query to match the general trends of the
raw water_level data.
We could do this with almost any InfluxQL function, but here we use
FIRST().
Focusing on the GROUP BY time() arguments in the query below, the first
argument (379m) matches the length of time that occurs between each peak and
trough of the water_level data.
The second argument (348m) is the
offset interval.
The offset interval alters InfluxDB’s default GROUP BY time() boundaries to
match the time range of the raw data.
The green line shows the results of the query:
SELECT first("water_level") FROM "h2o_feet" WHERE "location"='santa_monica' and time >= '2015-08-22 22:12:00' and time <= '2015-08-28 03:00:00' GROUP BY time(379m,348m)
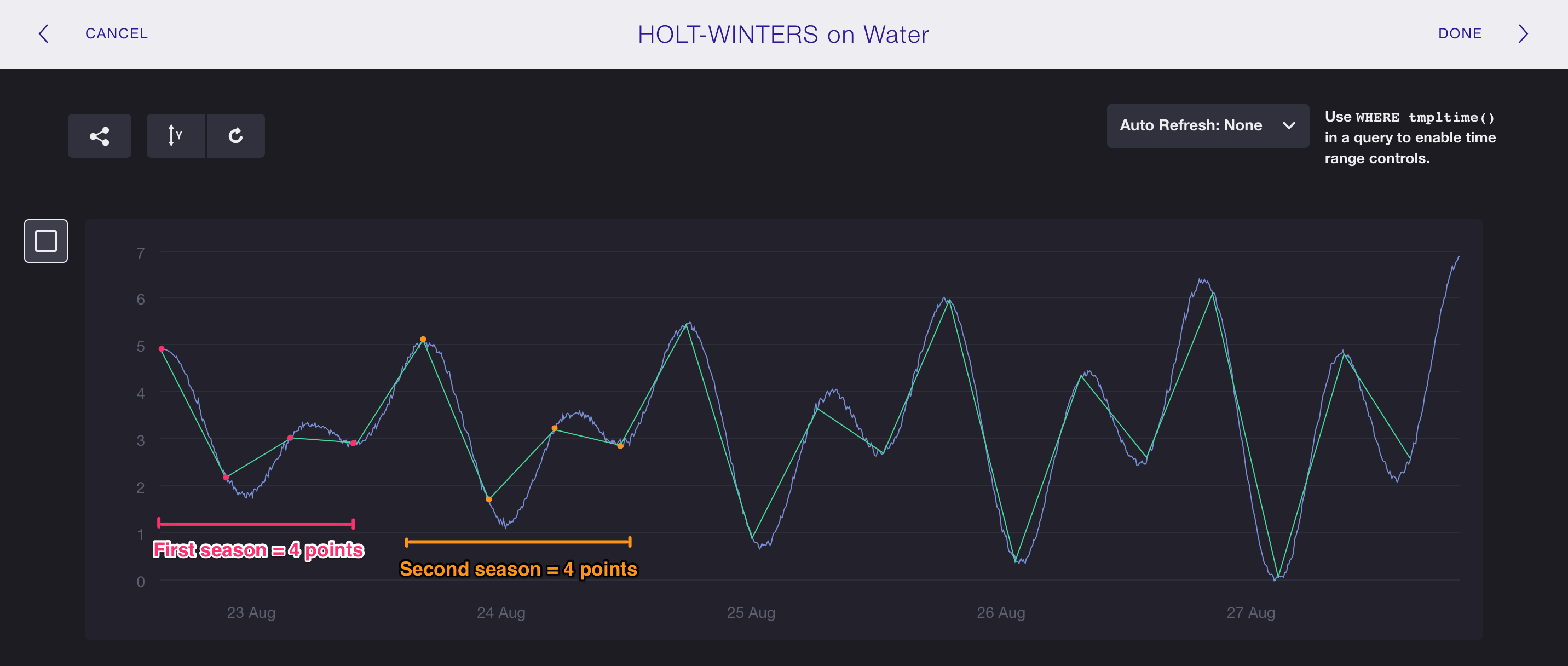
Step 2: Determine the Seasonal Pattern
Now that we have a query that matches the trends of the raw water_level data
it’s time to determine the seasonal pattern in the data.
We’ll use this information when we implement the HOLT_WINTERS() function in
the next step.
Focusing on the green line in the chart below, notice the pattern that repeats
about every 25 hours and 15 minutes.
That’s four data points per season, so 4 is our seasonal pattern argument.
Step 3: Include the HOLT_WINTERS() function
Now we add the HOLT_WINTERS() function to our query.
Here, we’ll use HOLT_WINTERS_WITH_FIT() so that the query results show both
the fitted values and the predicted values.
Focusing on the HOLT_WINTERS_WITH_FIT() arguments in the query below, the
first argument (10) tells the function to predict 10 data points.
Each point will be 379m apart, the same interval as the first argument in the
GROUP BY time() clause.
The second argument (4) is the seasonal pattern that we determined in the
previous step.
SELECT holt_winters_with_fit(first(water_level),10,4) FROM h2o_feet where location='santa_monica' and time >= '2015-08-22 22:12:00' and time <= '2015-08-28 03:00:00' group by time(379m,348m)
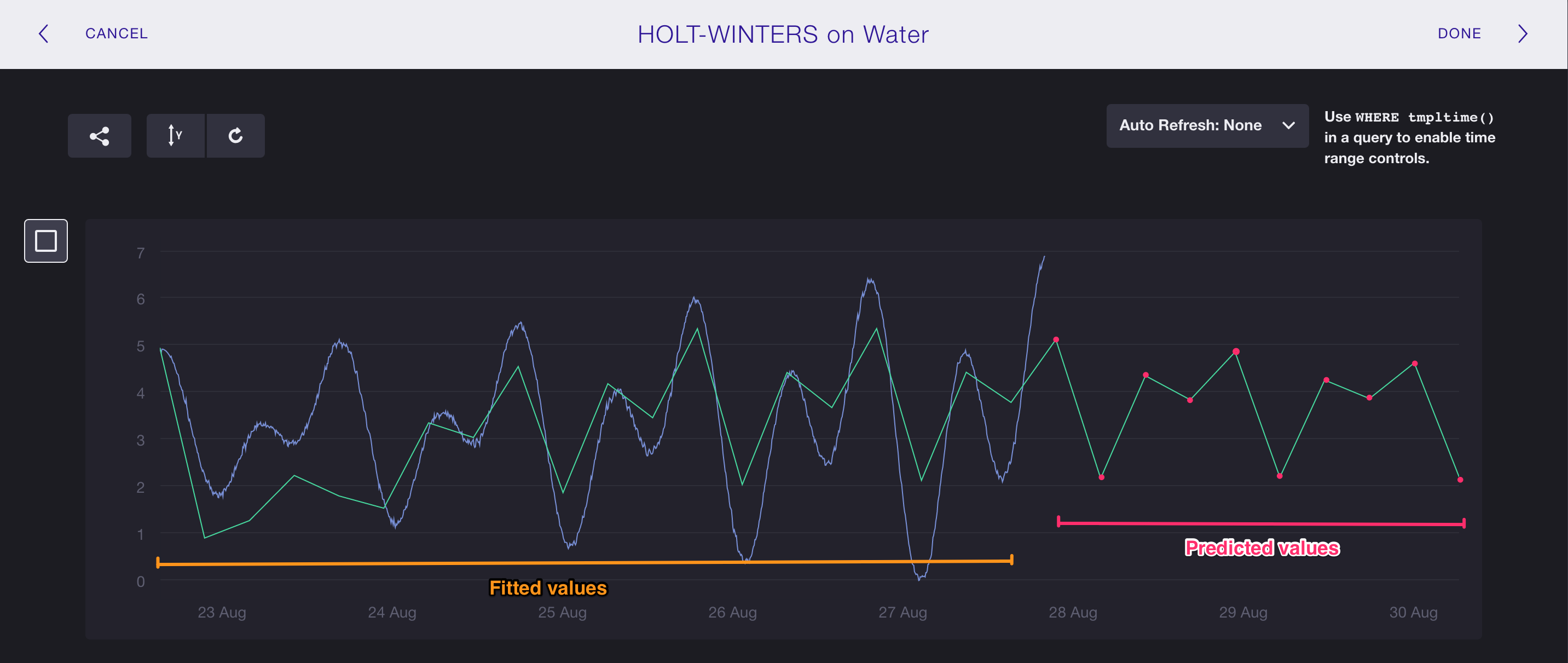
And that’s it! We’ve successfully predicted water levels in Santa Monica between August 28, 2015 at 04:32 and August 28, 2015 at 13:23.