This is archived documentation for InfluxData product versions that are no longer maintained. For newer documentation, see the latest InfluxData documentation.
Aggregate, select, transform, and predict data with InfluxQL functions.
Content
Aggregations
COUNT()
Returns the number of non-null field values.
Syntax
SELECT COUNT( [ * | <field_key> | /<regular_expression>/ ] ) [INTO_clause] FROM_clause [WHERE_clause] [GROUP_BY_clause] [ORDER_BY_clause] [LIMIT_clause] [OFFSET_clause] [SLIMIT_clause] [SOFFSET_clause]
Nested Syntax
SELECT COUNT(DISTINCT( [ * | <field_key> | /<regular_expression>/ ] )) [...]
Description of Syntax
COUNT(field_key)
Returns the number of field values associated with the field key.
COUNT(/regular_expression/)
Returns the number of field values associated with each field key that matches the regular expression.
COUNT(*)
Returns the number of field values associated with each field key in the measurement.
COUNT() supports all field value data types.
InfluxQL supports nesting DISTINCT() with COUNT().
Examples
Example 1: Count the field values associated with a field key
> SELECT COUNT("water_level") FROM "h2o_feet"
name: h2o_feet
time count
---- -----
1970-01-01T00:00:00Z 15258
The query returns the number of non-null field values in the water_level field key in the h2o_feet measurement.
Example 2: Count the field values associated with each field key in a measurement
> SELECT COUNT(*) FROM "h2o_feet"
name: h2o_feet
time count_level description count_water_level
---- ----------------------- -----------------
1970-01-01T00:00:00Z 15258 15258
The query returns the number of non-null field values for each field key associated with the h2o_feet measurement.
The h2o_feet measurement has two field keys: level description and water_level.
Example 3: Count the field values associated with each field key that matches a regular expression
> SELECT COUNT(/water/) FROM "h2o_feet"
name: h2o_feet
time count_water_level
---- -----------------
1970-01-01T00:00:00Z 15258
The query returns the number of non-null field values for every field key that contains the word water in the h2o_feet measurement.
Example 4: Count the field values associated with a field key and include several clauses
> SELECT COUNT("water_level") FROM "h2o_feet" WHERE time >= '2015-08-17T23:48:00Z' AND time <= '2015-08-18T00:54:00Z' GROUP BY time(12m),* fill(200) LIMIT 7 SLIMIT 1
name: h2o_feet
tags: location=coyote_creek
time count
---- -----
2015-08-17T23:48:00Z 200
2015-08-18T00:00:00Z 2
2015-08-18T00:12:00Z 2
2015-08-18T00:24:00Z 2
2015-08-18T00:36:00Z 2
2015-08-18T00:48:00Z 2
The query returns the number of non-null field values in the water_level field key.
It covers the time range between 2015-08-17T23:48:00Z and 2015-08-18T00:54:00Z and groups results into 12-minute time intervals and per tag.
The query fills empty time intervals with 200 and limits the number of points and series returned to seven and one.
Example 5: Count the distinct field values associated with a field key
> SELECT COUNT(DISTINCT("level description")) FROM "h2o_feet"
name: h2o_feet
time count
---- -----
1970-01-01T00:00:00Z 4
The query returns the number of unique field values for the level description field key and the h2o_feet measurement.
Common Issues with COUNT()
Issue 1: COUNT() and fill()
Most InfluxQL functions report null values for time intervals with no data, and
fill(<fill_option>)
replaces that null value with the fill_option.
COUNT() reports 0 for time intervals with no data, and fill(<fill_option>) replaces any 0 values with the fill_option.
Example
The first query in the codeblock below does not include fill().
The last time interval has no data so the reported value for that time interval is zero.
The second query includes fill(800000); it replaces the zero in the last interval with 800000.
> SELECT COUNT("water_level") FROM "h2o_feet" WHERE time >= '2015-09-18T21:24:00Z' AND time <= '2015-09-18T21:54:00Z' GROUP BY time(12m)
name: h2o_feet
time count
---- -----
2015-09-18T21:24:00Z 2
2015-09-18T21:36:00Z 2
2015-09-18T21:48:00Z 0
> SELECT COUNT("water_level") FROM "h2o_feet" WHERE time >= '2015-09-18T21:24:00Z' AND time <= '2015-09-18T21:54:00Z' GROUP BY time(12m) fill(800000)
name: h2o_feet
time count
---- -----
2015-09-18T21:24:00Z 2
2015-09-18T21:36:00Z 2
2015-09-18T21:48:00Z 800000
DISTINCT()
Returns the list of unique field values.
Syntax
SELECT DISTINCT( [ * | <field_key> | /<regular_expression>/ ] ) FROM_clause [WHERE_clause] [GROUP_BY_clause] [ORDER_BY_clause] [LIMIT_clause] [OFFSET_clause] [SLIMIT_clause] [SOFFSET_clause]
Nested Syntax
SELECT COUNT(DISTINCT( [ * | <field_key> | /<regular_expression>/ ] )) [...]
Description of Syntax
DISTINCT(field_key)
Returns the unique field values associated with the field key.
DISTINCT(/regular_expression/)
Returns the unique field values associated with each field key that matches the regular expression.
DISTINCT(*)
Returns the unique field values associated with each field key in the measurement.
DISTINCT() supports all field value data types.
InfluxQL supports nesting DISTINCT() with COUNT().
Examples
Example 1: List the distinct field values associated with a field key
> SELECT DISTINCT("level description") FROM "h2o_feet"
name: h2o_feet
time distinct
---- --------
1970-01-01T00:00:00Z between 6 and 9 feet
1970-01-01T00:00:00Z below 3 feet
1970-01-01T00:00:00Z between 3 and 6 feet
1970-01-01T00:00:00Z at or greater than 9 feet
The query returns a tabular list of the unique field values in the level description field key in the h2o_feet measurement.
Example 2: List the distinct field values associated with each field key in a measurement
> SELECT DISTINCT(*) FROM "h2o_feet"
name: h2o_feet
time distinct_level description distinct_water_level
---- -------------------------- --------------------
1970-01-01T00:00:00Z between 6 and 9 feet 8.12
1970-01-01T00:00:00Z between 3 and 6 feet 8.005
1970-01-01T00:00:00Z at or greater than 9 feet 7.887
1970-01-01T00:00:00Z below 3 feet 7.762
[...]
The query returns a tabular list of the unique field values for each field key in the h2o_feet measurement.
The h2o_feet measurement has two field keys: level description and water_level.
Example 3: List the distinct field values associated with each field key that matches a regular expression
> SELECT DISTINCT(/description/) FROM "h2o_feet"
name: h2o_feet
time distinct_level description
---- --------------------------
1970-01-01T00:00:00Z below 3 feet
1970-01-01T00:00:00Z between 6 and 9 feet
1970-01-01T00:00:00Z between 3 and 6 feet
1970-01-01T00:00:00Z at or greater than 9 feet
The query returns a tabular list of the unique field values for each field key in the h2o_feet measurement that contains the word description.
Example 4: List the distinct field values associated with a field key and include several clauses
> SELECT DISTINCT("level description") FROM "h2o_feet" WHERE time >= '2015-08-17T23:48:00Z' AND time <= '2015-08-18T00:54:00Z' GROUP BY time(12m),* SLIMIT 1
name: h2o_feet
tags: location=coyote_creek
time distinct
---- --------
2015-08-18T00:00:00Z between 6 and 9 feet
2015-08-18T00:12:00Z between 6 and 9 feet
2015-08-18T00:24:00Z between 6 and 9 feet
2015-08-18T00:36:00Z between 6 and 9 feet
2015-08-18T00:48:00Z between 6 and 9 feet
The query returns a tabular list of the unique field values in the level description field key.
It covers the time range between 2015-08-17T23:48:00Z and 2015-08-18T00:54:00Z and groups results into 12-minute time intervals and per tag.
The query also limits the number of series returned to one.
Example 5: Count the distinct field values associated with a field key
> SELECT COUNT(DISTINCT("level description")) FROM "h2o_feet"
name: h2o_feet
time count
---- -----
1970-01-01T00:00:00Z 4
The query returns the number of unique field values in the level description field key and the h2o_feet measurement.
Common Issues with DISTINCT()
Issue 1: DISTINCT() and the INTO clause
Using DISTINCT() with the INTO clause can cause InfluxDB to overwrite points in the destination measurement.
DISTINCT() often returns several results with the same timestamp; InfluxDB assumes points with the same series and timestamp are duplicate points and simply overwrites any duplicate point with the most recent point in the destination measurement.
Example
The first query in the codeblock below uses the DISTINCT() function and returns four results.
Notice that each result has the same timestamp.
The second query adds an INTO clause to the initial query and writes the query results to the distincts measurement.
The last query in the codeblock selects all the data in the distincts measurement.
The last query returns one point because the four initial results are duplicate points; they belong to the same series and have the same timestamp. When the system encounters duplicate points, it simply overwrites the previous point with the most recent point.
> SELECT DISTINCT("level description") FROM "h2o_feet"
name: h2o_feet
time distinct
---- --------
1970-01-01T00:00:00Z below 3 feet
1970-01-01T00:00:00Z between 6 and 9 feet
1970-01-01T00:00:00Z between 3 and 6 feet
1970-01-01T00:00:00Z at or greater than 9 feet
> SELECT DISTINCT("level description") INTO "distincts" FROM "h2o_feet"
name: result
time written
---- -------
1970-01-01T00:00:00Z 4
> SELECT * FROM "distincts"
name: distincts
time distinct
---- --------
1970-01-01T00:00:00Z at or greater than 9 feet
INTEGRAL()
INTEGRAL() is not yet functional.
See GitHub Issue #5930 for more information.
MEAN()
Returns the arithmetic mean (average) of field values.
Syntax
SELECT MEAN( [ * | <field_key> | /<regular_expression>/ ] ) [INTO_clause] FROM_clause [WHERE_clause] [GROUP_BY_clause] [ORDER_BY_clause] [LIMIT_clause] [OFFSET_clause] [SLIMIT_clause] [SOFFSET_clause]
Description of Syntax
MEAN(field_key)
Returns the average field value associated with the field key.
MEAN(/regular_expression/)
Returns the average field value associated with each field key that matches the regular expression.
MEAN(*)
Returns the average field value associated with each field key in the measurement.
MEAN() supports int64 and float64 field value data types.
Examples
Example 1: Calculate the mean field value associated with a field key
> SELECT MEAN("water_level") FROM "h2o_feet"
name: h2o_feet
time mean
---- ----
1970-01-01T00:00:00Z 4.442107025822522
The query returns the average field value in the water_level field key in the h2o_feet measurement.
Example 2: Calculate the mean field value associated with each field key in a measurement
> SELECT MEAN(*) FROM "h2o_feet"
name: h2o_feet
time mean_water_level
---- ----------------
1970-01-01T00:00:00Z 4.442107025822522
The query returns the average field value for every field key that stores numerical values in the h2o_feet measurement.
The h2o_feet measurement has one numerical field: water_level.
Example 3: Calculate the mean field value associated with each field key that matches a regular expression
> SELECT MEAN(/water/) FROM "h2o_feet"
name: h2o_feet
time mean_water_level
---- ----------------
1970-01-01T00:00:00Z 4.442107025822523
The query returns the average field value for each field key that stores numerical values and includes the word water in the h2o_feet measurement.
Example 4: Calculate the mean field value associated with a field key and include several clauses
> SELECT MEAN("water_level") FROM "h2o_feet" WHERE time >= '2015-08-17T23:48:00Z' AND time <= '2015-08-18T00:54:00Z' GROUP BY time(12m),* fill(9.01) LIMIT 7 SLIMIT 1
name: h2o_feet
tags: location=coyote_creek
time mean
---- ----
2015-08-17T23:48:00Z 9.01
2015-08-18T00:00:00Z 8.0625
2015-08-18T00:12:00Z 7.8245
2015-08-18T00:24:00Z 7.5675
2015-08-18T00:36:00Z 7.303
2015-08-18T00:48:00Z 7.046
The query returns the average of the values in the water_level field key.
It covers the time range between 2015-08-17T23:48:00Z and 2015-08-18T00:54:00Z and groups results into 12-minute time intervals and per tag.
The query fills empty time intervals with 9.01 and limits the number of points and series returned to seven and one.
MEDIAN()
Returns the middle value from a sorted list of field values.
Syntax
SELECT MEDIAN( [ * | <field_key> | /<regular_expression>/ ] ) [INTO_clause] FROM_clause [WHERE_clause] [GROUP_BY_clause] [ORDER_BY_clause] [LIMIT_clause] [OFFSET_clause] [SLIMIT_clause] [SOFFSET_clause]
Description of Syntax
MEDIAN(field_key)
Returns the middle field value associated with the field key.
MEDIAN(/regular_expression/)
Returns the middle field value associated with each field key that matches the regular expression.
MEDIAN(*)
Returns the middle field value associated with each field key in the measurement.
MEDIAN() supports int64 and float64 field value data types.
Note:
MEDIAN()is nearly equivalent toPERCENTILE(field_key, 50), exceptMEDIAN()returns the average of the two middle field values if the field contains an even number of values.
Examples
Example 1: Calculate the median field value associated with a field key
> SELECT MEDIAN("water_level") FROM "h2o_feet"
name: h2o_feet
time median
---- ------
1970-01-01T00:00:00Z 4.124
The query returns the middle field value in the water_level field key and in the h2o_feet measurement.
Example 2: Calculate the median field value associated with each field key in a measurement
> SELECT MEDIAN(*) FROM "h2o_feet"
name: h2o_feet
time median_water_level
---- ------------------
1970-01-01T00:00:00Z 4.124
The query returns the middle field value for every field key that stores numerical values in the h2o_feet measurement.
The h2o_feet measurement has one numerical field: water_level.
Example 3: Calculate the median field value associated with each field key that matches a regular expression
> SELECT MEDIAN(/water/) FROM "h2o_feet"
name: h2o_feet
time median_water_level
---- ------------------
1970-01-01T00:00:00Z 4.124
The query returns the middle field value for every field key that stores numerical values and includes the word water in the h2o_feet measurement.
Example 4: Calculate the median field value associated with a field key and include several clauses
> SELECT MEDIAN("water_level") FROM "h2o_feet" WHERE time >= '2015-08-17T23:48:00Z' AND time <= '2015-08-18T00:54:00Z' GROUP BY time(12m),* fill(700) LIMIT 7 SLIMIT 1 SOFFSET 1
name: h2o_feet
tags: location=santa_monica
time median
---- ------
2015-08-17T23:48:00Z 700
2015-08-18T00:00:00Z 2.09
2015-08-18T00:12:00Z 2.077
2015-08-18T00:24:00Z 2.0460000000000003
2015-08-18T00:36:00Z 2.0620000000000003
2015-08-18T00:48:00Z 700
The query returns the middle field value in the water_level field key.
It covers the time range between 2015-08-17T23:48:00Z and 2015-08-18T00:54:00Z and groups results into 12-minute time intervals and per tag.
The query fills empty time intervals with 700, limits the number of points and series returned to seven and one, and offsets the series returned by one.
MODE()
Returns the most frequent value in a list of field values.
Syntax
SELECT MODE( [ * | <field_key> | /<regular_expression>/ ] ) [INTO_clause] FROM_clause [WHERE_clause] [GROUP_BY_clause] [ORDER_BY_clause] [LIMIT_clause] [OFFSET_clause] [SLIMIT_clause] [SOFFSET_clause]
Description of Syntax
MODE(field_key)
Returns the most frequent field value associated with the field key.
MODE(/regular_expression/)
Returns the most frequent field value associated with each field key that matches the regular expression.
MODE(*)
Returns the most frequent field value associated with each field key in the measurement.
MODE() supports all field value data types.
Note:
MODE()returns the field value with the earliest timestamp if there’s a tie between two or more values for the maximum number of occurrences.
Examples
Example 1: Calculate the mode field value associated with a field key
> SELECT MODE("level description") FROM "h2o_feet"
name: h2o_feet
time mode
---- ----
1970-01-01T00:00:00Z between 3 and 6 feet
The query returns the most frequent field value in the level description field key and in the h2o_feet measurement.
Example 2: Calculate the mode field value associated with each field key in a measurement
> SELECT MODE(*) FROM "h2o_feet"
name: h2o_feet
time mode_level description mode_water_level
---- ---------------------- ----------------
1970-01-01T00:00:00Z between 3 and 6 feet 2.69
The query returns the most frequent field value for every field key in the h2o_feet measurement.
The h2o_feet measurement has two field keys: level description and water_level.
Example 3: Calculate the mode field value associated with each field key that matches a regular expression
> SELECT MODE(/water/) FROM "h2o_feet"
name: h2o_feet
time mode_water_level
---- ----------------
1970-01-01T00:00:00Z 2.69
The query returns the most frequent field value for every field key that includes the word /water/ in the h2o_feet measurement.
Example 4: Calculate the mode field value associated with a field key and include several clauses
> SELECT MODE("level description") FROM "h2o_feet" WHERE time >= '2015-08-17T23:48:00Z' AND time <= '2015-08-18T00:54:00Z' GROUP BY time(12m),* LIMIT 3 SLIMIT 1 SOFFSET 1
name: h2o_feet
tags: location=santa_monica
time mode
---- ----
2015-08-17T23:48:00Z
2015-08-18T00:00:00Z below 3 feet
2015-08-18T00:12:00Z below 3 feet
The query returns the mode of the values associated with the water_level field key.
It covers the time range between 2015-08-17T23:48:00Z and 2015-08-18T00:54:00Z and groups results into 12-minute time intervals and per tag.
The query limits the number of points and series returned to three and one, and it offsets the series returned by one.
SPREAD()
Returns the difference between the minimum and maximum field values.
Syntax
SELECT SPREAD( [ * | <field_key> | /<regular_expression>/ ] ) [INTO_clause] FROM_clause [WHERE_clause] [GROUP_BY_clause] [ORDER_BY_clause] [LIMIT_clause] [OFFSET_clause] [SLIMIT_clause] [SOFFSET_clause]
Description of Syntax
SPREAD(field_key)
Returns the difference between the minimum and maximum field values associated with the field key.
SPREAD(/regular_expression/)
Returns the difference between the minimum and maximum field values associated with each field key that matches the regular expression.
SPREAD(*)
Returns the difference between the minimum and maximum field values associated with each field key in the measurement.
SPREAD() supports int64 and float64 field value data types.
Examples
Example 1: Calculate the spread for the field values associated with a field key
> SELECT SPREAD("water_level") FROM "h2o_feet"
name: h2o_feet
time spread
---- ------
1970-01-01T00:00:00Z 10.574
The query returns the difference between the minimum and maximum field values in the water_level field key and in the h2o_feet measurement.
Example 2: Calculate the spread for the field values associated with each field key in a measurement
> SELECT SPREAD(*) FROM "h2o_feet"
name: h2o_feet
time spread_water_level
---- ------------------
1970-01-01T00:00:00Z 10.574
The query returns the difference between the minimum and maximum field values for every field key that stores numerical values in the h2o_feet measurement.
The h2o_feet measurement has one numerical field: water_level.
Example 3: Calculate the spread for the field values associated with each field key that matches a regular expression
> SELECT SPREAD(/water/) FROM "h2o_feet"
name: h2o_feet
time spread_water_level
---- ------------------
1970-01-01T00:00:00Z 10.574
The query returns the difference between the minimum and maximum field values for every field key that stores numerical values and includes the word water in the h2o_feet measurement.
Example 4: Calculate the spread for the field values associated with a field key and include several clauses
> SELECT SPREAD("water_level") FROM "h2o_feet" WHERE time >= '2015-08-17T23:48:00Z' AND time <= '2015-08-18T00:54:00Z' GROUP BY time(12m),* fill(18) LIMIT 3 SLIMIT 1 SOFFSET 1
name: h2o_feet
tags: location=santa_monica
time spread
---- ------
2015-08-17T23:48:00Z 18
2015-08-18T00:00:00Z 0.052000000000000046
2015-08-18T00:12:00Z 0.09799999999999986
The query returns the difference between the minimum and maximum field values in the water_level field key.
It covers the time range between 2015-08-17T23:48:00Z and 2015-08-18T00:54:00Zand groups results into 12-minute time intervals and per tag.
The query fills empty time intervals with 18, limits the number of points and series returned to three and one, and offsets the series returned by one.
STDDEV()
Returns the standard deviation of field values.
Syntax
SELECT STDDEV( [ * | <field_key> | /<regular_expression>/ ] ) [INTO_clause] FROM_clause [WHERE_clause] [GROUP_BY_clause] [ORDER_BY_clause] [LIMIT_clause] [OFFSET_clause] [SLIMIT_clause] [SOFFSET_clause]
Description of Syntax
STDDEV(field_key)
Returns the standard deviation of field values associated with the field key.
STDDEV(/regular_expression/)
Returns the standard deviation of field values associated with each field key that matches the regular expression.
STDDEV(*)
Returns the standard deviation of field values associated with each field key in the measurement.
STDDEV() supports int64 and float64 field value data types.
Examples
Example 1: Calculate the standard deviation for the field values associated with a field key
> SELECT STDDEV("water_level") FROM "h2o_feet"
name: h2o_feet
time stddev
---- ------
1970-01-01T00:00:00Z 2.279144584196141
The query returns the standard deviation of the field values in the water_level field key and in the h2o_feet measurement.
Example 2: Calculate the standard deviation for the field values associated with each field key in a measurement
> SELECT STDDEV(*) FROM "h2o_feet"
name: h2o_feet
time stddev_water_level
---- ------------------
1970-01-01T00:00:00Z 2.279144584196141
The query returns the standard deviation of the field values for each field key that stores numerical values in the h2o_feet measurement.
The h2o_feet measurement has one numerical field: water_level.
Example 3: Calculate the standard deviation for the field values associated with each field key that matches a regular expression
> SELECT STDDEV(/water/) FROM "h2o_feet"
name: h2o_feet
time stddev_water_level
---- ------------------
1970-01-01T00:00:00Z 2.279144584196141
The query returns the standard deviation of the field values for each field key that stores numerical values and includes the word water in the h2o_feet measurement.
Example 4: Calculate the standard deviation for the field values associated with a field key and include several clauses
> SELECT STDDEV("water_level") FROM "h2o_feet" WHERE time >= '2015-08-17T23:48:00Z' AND time <= '2015-08-18T00:54:00Z' GROUP BY time(12m),* fill(18000) LIMIT 2 SLIMIT 1 SOFFSET 1
name: h2o_feet
tags: location=santa_monica
time stddev
---- ------
2015-08-17T23:48:00Z 18000
2015-08-18T00:00:00Z 0.03676955262170051
The query returns the standard deviation of the field values in the water_level field key.
It covers the time range between 2015-08-17T23:48:00Z and 2015-08-18T00:54:00Z and groups results into 12-minute time intervals and per tag.
The query fills empty time intervals with 18000, limits the number of points and series returned to two and one, and offsets the series returned by one.
SUM()
Returns the sum of field values.
Syntax
SELECT SUM( [ * | <field_key> | /<regular_expression>/ ] ) [INTO_clause] FROM_clause [WHERE_clause] [GROUP_BY_clause] [ORDER_BY_clause] [LIMIT_clause] [OFFSET_clause] [SLIMIT_clause] [SOFFSET_clause]
Description of Syntax
SUM(field_key)
Returns the sum of field values associated with the field key.
SUM(/regular_expression/)
Returns the sum of field values associated with each field key that matches the regular expression.
SUM(*)
Returns the sums of field values associated with each field key in the measurement.
SUM() supports int64 and float64 field value data types.
Examples:
Example 1: Calculate the sum of the field values associated with a field key
> SELECT SUM("water_level") FROM "h2o_feet"
name: h2o_feet
time sum
---- ---
1970-01-01T00:00:00Z 67777.66900000004
The query returns the summed total of the field values in the water_level field key and in the h2o_feet measurement.
Example 2: Calculate the sum of the field values associated with each field key in a measurement
> SELECT SUM(*) FROM "h2o_feet"
name: h2o_feet
time sum_water_level
---- ---------------
1970-01-01T00:00:00Z 67777.66900000004
The query returns the summed total of the field values for each field key that stores numerical values in the h2o_feet measurement.
The h2o_feet measurement has one numerical field: water_level.
Example 3: Calculate the sum of the field values associated with each field key that matches a regular expression
> SELECT SUM(/water/) FROM "h2o_feet"
name: h2o_feet
time sum_water_level
---- ---------------
1970-01-01T00:00:00Z 67777.66900000004
The query returns the summed total of the field values for each field key that stores numerical values and includes the word water in the h2o_feet measurement.
Example 4: Calculate the sum of the field values associated with a field key and include several clauses
> SELECT SUM("water_level") FROM "h2o_feet" WHERE time >= '2015-08-17T23:48:00Z' AND time <= '2015-08-18T00:54:00Z' GROUP BY time(12m),* fill(18000) LIMIT 4 SLIMIT 1
name: h2o_feet
tags: location=coyote_creek
time sum
---- ---
2015-08-17T23:48:00Z 18000
2015-08-18T00:00:00Z 16.125
2015-08-18T00:12:00Z 15.649
2015-08-18T00:24:00Z 15.135
The query returns the summed total of the field values in the water_level field key.
It covers the time range between 2015-08-17T23:48:00Z and 2015-08-18T00:54:00Z and groups results into 12-minute time intervals and per tag. The query fills empty time intervals with 18000, and it limits the number of points and series returned to four and one.
Selectors
BOTTOM()
Returns the smallest N field values.
Syntax
SELECT BOTTOM(<field_key>[,<tag_key(s)>],<N> )[,<tag_key(s)>|<field_key(s)>] [INTO_clause] FROM_clause [WHERE_clause] [GROUP_BY_clause] [ORDER_BY_clause] [LIMIT_clause] [OFFSET_clause] [SLIMIT_clause] [SOFFSET_clause]
Description of Syntax
BOTTOM(field_key,N)
Returns the smallest N field values associated with the field key.
BOTTOM(field_key,tag_key(s),N)
Returns the smallest field value for N tag values of the tag key.
BOTTOM(field_key,N),tag_key(s),field_key(s)
Returns the smallest N field values associated with the field key in the parentheses and the relevant tag and/or field.
BOTTOM() supports int64 and float64 field value data types.
Note:
BOTTOM()returns the field value with the earliest timestamp if there’s a tie between two or more values for the smallest value.
Examples
Example 1: Select the bottom three field values associated with a field key
> SELECT BOTTOM("water_level",3) FROM "h2o_feet"
name: h2o_feet
time bottom
---- ------
2015-08-29T14:30:00Z -0.61
2015-08-29T14:36:00Z -0.591
2015-08-30T15:18:00Z -0.594
The query returns the smallest three field values in the water_level field key and in the h2o_feet measurement.
Example 2: Select the bottom field value associated with a field key for two tags
> SELECT BOTTOM("water_level","location",2) FROM "h2o_feet"
name: h2o_feet
time bottom location
---- ------ --------
2015-08-29T10:36:00Z -0.243 santa_monica
2015-08-29T14:30:00Z -0.61 coyote_creek
The query returns the smallest field values in the water_level field key for two tag values associated with the location tag key.
Example 3: Select the bottom four field values associated with a field key and the relevant tags and fields
> SELECT BOTTOM("water_level",4),"location","level description" FROM "h2o_feet"
name: h2o_feet
time bottom location level description
---- ------ -------- -----------------
2015-08-29T14:24:00Z -0.587 coyote_creek below 3 feet
2015-08-29T14:30:00Z -0.61 coyote_creek below 3 feet
2015-08-29T14:36:00Z -0.591 coyote_creek below 3 feet
2015-08-30T15:18:00Z -0.594 coyote_creek below 3 feet
The query returns the smallest four field values in the water_level field key and the relevant values of the location tag key and the level description field key.
Example 4: Select the bottom three field values associated with a field key and include several clauses
> SELECT BOTTOM("water_level",3),"location" FROM "h2o_feet" WHERE time >= '2015-08-18T00:00:00Z' AND time <= '2015-08-18T00:54:00Z' GROUP BY time(24m) ORDER BY time DESC
name: h2o_feet
time bottom location
---- ------ --------
2015-08-18T00:48:00Z 1.991 santa_monica
2015-08-18T00:48:00Z 2.054 santa_monica
2015-08-18T00:48:00Z 6.982 coyote_creek
2015-08-18T00:24:00Z 2.041 santa_monica
2015-08-18T00:24:00Z 2.051 santa_monica
2015-08-18T00:24:00Z 2.057 santa_monica
2015-08-18T00:00:00Z 2.028 santa_monica
2015-08-18T00:00:00Z 2.064 santa_monica
2015-08-18T00:00:00Z 2.116 santa_monica
The query returns the smallest three values in the water_level field key for each 24-minute interval between 2015-08-18T00:00:00Z and 2015-08-18T00:54:00Z.
It also returns results in descending timestamp order.
Notice that the GROUP BY time() clause overrides the points’ original timestamps.
The timestamps in the results indicate the the start of each 24-minute time interval;
the last three points in the results are for the time interval between 2015-08-18T00:00:00Z and just before 2015-08-18T00:24:00Z.
Common Issues with BOTTOM()
Issue 1: BOTTOM(), the INTO clause, and the GROUP BY time() clause
Using the BOTTOM() function with the INTO clause
and the GROUP BY time() clause can cause InfluxDB to overwrite points in the destination measurement.
Using BOTTOM() with the GROUP BY time() clause often returns several results with the same timestamp; InfluxDB assumes points with the same series and timestamp are duplicate points and simply overwrites any duplicate point with the most recent point in the destination measurement.
Example
The first query in the codeblock below uses the BOTTOM() function with a GROUP BY time() clause, and it returns four results.
Notice that the first two results have the same timestamp and the last two results have the same timestamp.
The second query adds an INTO clause to the initial query and writes the query results to the bottom_dweller measurement.
The last query in the codeblock selects all the data in the bottom_dweller measurement.
The last query returns two points instead of four points, because two of the initial results are duplicate points; they belong to the same series and have the same timestamp. When the system encounters duplicate points, it simply overwrites the previous point with the most recent point.
> SELECT BOTTOM("water_level",2),"location" FROM "h2o_feet" WHERE time >= '2015-08-18T00:00:00Z' AND time <= '2015-08-18T00:24:00Z' GROUP BY time(24m)
name: h2o_feet
time bottom location
---- ------ --------
2015-08-18T00:00:00Z 2.028 santa_monica
2015-08-18T00:00:00Z 2.064 santa_monica
2015-08-18T00:24:00Z 2.041 santa_monica
2015-08-18T00:24:00Z 7.635 coyote_creek
> SELECT BOTTOM("water_level",2),"location" INTO "bottom_dweller" FROM "h2o_feet" WHERE time >= '2015-08-18T00:00:00Z' AND time <= '2015-08-18T00:24:00Z' GROUP BY time(24m)
name: result
time written
---- -------
1970-01-01T00:00:00Z 4
> SELECT * FROM "bottom_dweller"
name: bottom_dweller
time bottom location
---- ------ --------
2015-08-18T00:00:00Z 2.064 santa_monica
2015-08-18T00:24:00Z 7.635 coyote_creek
Issue 2: BOTTOM() and a tag key with fewer than N tag values
Queries with the syntax SELECT BOTTOM(<field_key>,<tag_key>,<N>) can return fewer points than expected.
If the tag key has X tag values, the query specifies N values, and X is smaller than N, then the query returns X points.
Example
The query below asks for the smallest field values of water_level for three tag values of the location tag key.
Because the location tag key has two tag values (santa_monica and coyote_creek), the query returns two points instead of three.
> SELECT BOTTOM("water_level","location",3) FROM "h2o_feet"
name: h2o_feet
time bottom location
---- ------ --------
2015-08-29T10:36:00Z -0.243 santa_monica
2015-08-29T14:30:00Z -0.61 coyote_creek
FIRST()
Returns the field value with the oldest timestamp.
Syntax
SELECT FIRST(<field_key>)[,<tag_key(s)>|<field_key(s)>] [INTO_clause] FROM_clause [WHERE_clause] [GROUP_BY_clause] [ORDER_BY_clause] [LIMIT_clause] [OFFSET_clause] [SLIMIT_clause] [SOFFSET_clause]
Description of Syntax
FIRST(field_key)
Returns the oldest field value (determined by timestamp) associated with the field key.
FIRST(/regular_expression/)
Returns the oldest field value (determined by timestamp) associated with each field key that matches the regular expression.
FIRST(*)
Returns the oldest field value (determined by timestamp) associated with each field key in the measurement.
FIRST(field_key),tag_key(s),field_key(s)
Returns the oldest field value (determined by timestamp) associated with the field key in the parentheses and the relevant tag and/or field.
FIRST() supports all field value data types.
Examples
Example 1: Select the first field value associated with a field key
> SELECT FIRST("level description") FROM "h2o_feet"
name: h2o_feet
time first
---- -----
2015-08-18T00:00:00Z between 6 and 9 feet
The query returns the oldest field value (determined by timestamp) associated with the level description field key and in the h2o_feet measurement.
Example 2: Select the first field value associated with each field key in a measurement
> SELECT FIRST(*) FROM "h2o_feet"
name: h2o_feet
time first_level description first_water_level
---- ----------------------- -----------------
1970-01-01T00:00:00Z between 6 and 9 feet 8.12
The query returns the oldest field value (determined by timestamp) for each field key in the h2o_feet measurement.
The h2o_feet measurement has two field keys: level description and water_level.
Example 3: Select the first field value associated with each field key that matches a regular expression
> SELECT FIRST(/level/) FROM "h2o_feet"
name: h2o_feet
time first_level description first_water_level
---- ----------------------- -----------------
1970-01-01T00:00:00Z between 6 and 9 feet 8.12
The query returns the oldest field value for each field key that includes the word level in the h2o_feet measurement.
Example 4: Select the first value associated with a field key and the relevant tags and fields
> SELECT FIRST("level description"),"location","water_level" FROM "h2o_feet"
name: h2o_feet
time first location water_level
---- ----- -------- -----------
2015-08-18T00:00:00Z between 6 and 9 feet coyote_creek 8.12
The query returns the oldest field value (determined by timestamp) in the level description field key and the relevant values of the location tag key and the water_level field key.
Example 5: Select the first field value associated with a field key and include several clauses
> SELECT FIRST("water_level") FROM "h2o_feet" WHERE time >= '2015-08-17T23:48:00Z' AND time <= '2015-08-18T00:54:00Z' GROUP BY time(12m),* fill(9.01) LIMIT 4 SLIMIT 1
name: h2o_feet
tags: location=coyote_creek
time first
---- -----
2015-08-17T23:48:00Z 9.01
2015-08-18T00:00:00Z 8.12
2015-08-18T00:12:00Z 7.887
2015-08-18T00:24:00Z 7.635
The query returns the oldest field value (determined by timestamp) in the water_level field key.
It covers the time range between 2015-08-17T23:48:00Z and 2015-08-18T00:54:00Z and groups results into 12-minute time intervals and per tag.
The query fills empty time intervals with 9.01, and it limits the number of points and series returned to four and one.
Notice that the GROUP BY time() clause overrides the points’ original timestamps.
The timestamps in the results indicate the the start of each 12-minute time interval;
the first point in the results covers the time interval between 2015-08-17T23:48:00Z and just before 2015-08-18T00:00:00Z and the last point in the results covers the time interval between 2015-08-18T00:24:00Z and just before 2015-08-18T00:36:00Z.
LAST()
Returns the field value with the most recent timestamp.
Syntax
SELECT LAST(<field_key>)[,<tag_key(s)>|<field_keys(s)>] [INTO_clause] FROM_clause [WHERE_clause] [GROUP_BY_clause] [ORDER_BY_clause] [LIMIT_clause] [OFFSET_clause] [SLIMIT_clause] [SOFFSET_clause]
Description of Syntax
LAST(field_key)
Returns the newest field value (determined by timestamp) associated with the field key.
LAST(/regular_expression/)
Returns the newest field value (determined by timestamp) associated with each field key that matches the regular expression.
LAST(*)
Returns the newest field value (determined by timestamp) associated with each field key in the measurement.
LAST(field_key),tag_key(s),field_key(s)
Returns the newest field value (determined by timestamp) associated with the field key in the parentheses and the relevant tag and/or field.
LAST() supports all field value data types.
Examples
Example 1: Select the last field values associated with a field key
> SELECT LAST("level description") FROM "h2o_feet"
name: h2o_feet
time last
---- ----
2015-09-18T21:42:00Z between 3 and 6 feet
The query returns the newest field value (determined by timestamp) associated with the level description field key and in the h2o_feet measurement.
Example 2: Select the last field values associated with each field key in a measurement
> SELECT LAST(*) FROM "h2o_feet"
name: h2o_feet
time first_level description first_water_level
---- ----------------------- -----------------
1970-01-01T00:00:00Z between 3 and 6 feet 4.938
The query returns the newest field value (determined by timestamp) for each field key in the h2o_feet measurement.
The h2o_feet measurement has two field keys: level description and water_level.
Example 3: Select the last field value associated with each field key that matches a regular expression
> SELECT LAST(/level/) FROM "h2o_feet"
name: h2o_feet
time first_level description first_water_level
---- ----------------------- -----------------
1970-01-01T00:00:00Z between 3 and 6 feet 4.938
The query returns the newest field value for each field key that includes the word level in the h2o_feet measurement.
Example 4: Select the last field value associated with a field key and the relevant tags and fields
> SELECT LAST("level description"),"location","water_level" FROM "h2o_feet"
name: h2o_feet
time last location water_level
---- ---- -------- -----------
2015-09-18T21:42:00Z between 3 and 6 feet santa_monica 4.938
The query returns the newest field value (determined by timestamp) in the level description field key and the relevant values of the location tag key and the water_level field key.
Example 5: Select the last field value associated with a field key and include several clauses
> SELECT LAST("water_level") FROM "h2o_feet" WHERE time >= '2015-08-17T23:48:00Z' AND time <= '2015-08-18T00:54:00Z' GROUP BY time(12m),* fill(9.01) LIMIT 4 SLIMIT 1
name: h2o_feet
tags: location=coyote_creek
time last
---- ----
2015-08-17T23:48:00Z 9.01
2015-08-18T00:00:00Z 8.005
2015-08-18T00:12:00Z 7.762
2015-08-18T00:24:00Z 7.5
The query returns the newest field value (determined by timestamp) in the water_level field key.
It covers the time range between 2015-08-17T23:48:00Z and 2015-08-18T00:54:00Z and groups results into 12-minute time intervals and per tag.
The query fills empty time intervals with 9.01, and it limits the number of points and series returned to four and one.
Notice that the GROUP BY time() clause overrides the points’ original timestamps.
The timestamps in the results indicate the the start of each 12-minute time interval;
the first point in the results covers the time interval between 2015-08-17T23:48:00Z and just before 2015-08-18T00:00:00Z and the last point in the results covers the time interval between 2015-08-18T00:24:00Z and just before 2015-08-18T00:36:00Z.
MAX()
Returns the greatest field value.
Syntax
SELECT MAX(<field_key>)[,<tag_key(s)>|<field__key(s)>] [INTO_clause] FROM_clause [WHERE_clause] [GROUP_BY_clause] [ORDER_BY_clause] [LIMIT_clause] [OFFSET_clause] [SLIMIT_clause] [SOFFSET_clause]
Description of Syntax
MAX(field_key)
Returns the greatest field value associated with the field key.
MAX(/regular_expression/)
Returns the greatest field value associated with each field key that matches the regular expression.
MAX(*)
Returns the greatest field value associated with each field key in the measurement.
MAX(field_key),tag_key(s),field_key(s)
Returns the greatest field value associated with the field key in the parentheses and the relevant tag and/or field.
MAX() supports int64 and float64 field value data types.
Examples
Example 1: Select the maximum field value associated with a field key
> SELECT MAX("water_level") FROM "h2o_feet"
name: h2o_feet
time max
---- ---
2015-08-29T07:24:00Z 9.964
The query returns the greatest field value in the water_level field key and in the h2o_feet measurement.
Example 2: Select the maximum field value associated with each field key in a measurement
> SELECT MAX(*) FROM "h2o_feet"
name: h2o_feet
time max_water_level
---- ---------------
2015-08-29T07:24:00Z 9.964
The query returns the greatest field value for each field key that stores numerical values in the h2o_feet measurement.
The h2o_feet measurement has one numerical field: water_level.
Example 3: Select the maximum field value associated with each field key that matches a regular expression
> SELECT MAX(/level/) FROM "h2o_feet"
name: h2o_feet
time max_water_level
---- ---------------
2015-08-29T07:24:00Z 9.964
The query returns the greatest field value for each field key that stores numerical values and includes the word water in the h2o_feet measurement.
Example 4: Select the maximum field value associated with a field key and the relevant tags and fields
> SELECT MAX("water_level"),"location","level description" FROM "h2o_feet"
name: h2o_feet
time max location level description
---- --- -------- -----------------
2015-08-29T07:24:00Z 9.964 coyote_creek at or greater than 9 feet
The query returns the greatest field value in the water_level field key and the relevant values of the location tag key and the level description field key.
Example 5: Select the maximum field value associated with a field key and include several clauses
> SELECT MAX("water_level") FROM "h2o_feet" WHERE time >= '2015-08-17T23:48:00Z' AND time <= '2015-08-18T00:54:00Z' GROUP BY time(12m),* fill(9.01) LIMIT 4 SLIMIT 1
name: h2o_feet
tags: location=coyote_creek
time max
---- ---
2015-08-17T23:48:00Z 9.01
2015-08-18T00:00:00Z 8.12
2015-08-18T00:12:00Z 7.887
2015-08-18T00:24:00Z 7.635
The query returns the greatest field value in the water_level field key.
It covers the time range between 2015-08-17T23:48:00Z and 2015-08-18T00:54:00Z and groups results in to 12-minute time intervals and per tag.
The query fills empty time intervals with 9.01, and it limits the number of points and series returned to four and one.
Notice that the GROUP BY time() clause overrides the points’ original timestamps.
The timestamps in the results indicate the the start of each 12-minute time interval;
the first point in the results covers the time interval between 2015-08-17T23:48:00Z and just before 2015-08-18T00:00:00Z and the last point in the results covers the time interval between 2015-08-18T00:24:00Z and just before 2015-08-18T00:36:00Z.
MIN()
Returns the lowest field value.
Syntax
SELECT MIN(<field_key>)[,<tag_key(s)>|<field_key(s)>] [INTO_clause] FROM_clause [WHERE_clause] [GROUP_BY_clause] [ORDER_BY_clause] [LIMIT_clause] [OFFSET_clause] [SLIMIT_clause] [SOFFSET_clause]
Description of Syntax
MIN(field_key)
Returns the lowest field value associated with the field key.
MIN(/regular_expression/)
Returns the lowest field value associated with each field key that matches the regular expression.
MIN(*)
Returns the lowest field value associated with each field key in the measurement.
MIN(field_key),tag_key(s),field_key(s)
Returns the lowest field value associated with the field key in the parentheses and the relevant tag and/or field.
MIN() supports int64 and float64 field value data types.
Examples
Example 1: Select the minimum field value associated with a field key
> SELECT MIN("water_level") FROM "h2o_feet"
name: h2o_feet
time min
---- ---
2015-08-29T14:30:00Z -0.61
The query returns the lowest field value in the water_level field key and in the h2o_feet measurement.
Example 2: Select the minimum field value associated with each field key in a measurement
> SELECT MIN(*) FROM "h2o_feet"
name: h2o_feet
time min_water_level
---- ---------------
2015-08-29T14:30:00Z -0.61
The query returns the lowest field value for each field key that stores numerical values in the h2o_feet measurement.
The h2o_feet measurement has one numerical field: water_level.
Example 3: Select the minimum field value associated with each field key that matches a regular expression
> SELECT MIN(/level/) FROM "h2o_feet"
name: h2o_feet
time min_water_level
---- ---------------
2015-08-29T14:30:00Z -0.61
The query returns the lowest field value for each field key that stores numerical values and includes the word water in the h2o_feet measurement.
Example 4: Select the minimum field value associated with a field key and the relevant tags and fields
> SELECT MIN("water_level"),"location","level description" FROM "h2o_feet"
name: h2o_feet
time min location level description
---- --- -------- -----------------
2015-08-29T14:30:00Z -0.61 coyote_creek below 3 feet
The query returns the lowest field value in the water_level field key and the relevant values of the location tag key and the level description field key.
Example 5: Select the minimum field value associated with a field key and include several clauses
> SELECT MIN("water_level") FROM "h2o_feet" WHERE time >= '2015-08-17T23:48:00Z' AND time <= '2015-08-18T00:54:00Z' GROUP BY time(12m),* fill(9.01) LIMIT 4 SLIMIT 1
name: h2o_feet
tags: location=coyote_creek
time min
---- ---
2015-08-17T23:48:00Z 9.01
2015-08-18T00:00:00Z 8.005
2015-08-18T00:12:00Z 7.762
2015-08-18T00:24:00Z 7.5
The query returns the lowest field value in the water_level field key.
It covers the time range between 2015-08-17T23:48:00Z and 2015-08-18T00:54:00Z and groups results in to 12-minute time intervals and per tag.
The query fills empty time intervals with 9.01, and it limits the number of points and series returned to four and one.
Notice that the GROUP BY time() clause overrides the points’ original timestamps.
The timestamps in the results indicate the the start of each 12-minute time interval;
the first point in the results covers the time interval between 2015-08-17T23:48:00Z and just before 2015-08-18T00:00:00Z and the last point in the results covers the time interval between 2015-08-18T00:24:00Z and just before 2015-08-18T00:36:00Z.
PERCENTILE()
Returns the Nth percentile field value.
Syntax
SELECT PERCENTILE(<field_key>, <N>)[,<tag_key(s)>|<field_key(s)>] [INTO_clause] FROM_clause [WHERE_clause] [GROUP_BY_clause] [ORDER_BY_clause] [LIMIT_clause] [OFFSET_clause] [SLIMIT_clause] [SOFFSET_clause]
Description of Syntax
PERCENTILE(field_key,N)
Returns the Nth percentile field value associated with the field key.
PERCENTILE(/regular_expression/,N)
Returns the Nth percentile field value associated with each field key that matches the regular expression.
PERCENTILE(*,N)
Returns the Nth percentile field value associated with each field key in the measurement.
PERCENTILE(field_key,N),tag_key(s),field_key(s)
Returns the Nth percentile field value associated with the field key in the parentheses and the relevant tag and/or field.
N must be an integer or floating point number between 0 and 100, inclusive.
PERCENTILE() supports int64 and float64 field value data types.
Examples
Example 1: Select the fifth percentile field value associated with a field key
> SELECT PERCENTILE("water_level",5) FROM "h2o_feet"
name: h2o_feet
time percentile
---- ----------
2015-08-31T03:42:00Z 1.122
The query returns the field value that is larger than five percent of the field values in the water_level field key and in the h2o_feet measurement.
Example 2: Select the fifth percentile field value associated with each field key in a measurement
> SELECT PERCENTILE(*,5) FROM "h2o_feet"
name: h2o_feet
time percentile_water_level
---- ----------------------
2015-08-31T03:42:00Z 1.122
The query returns the field value that is larger than five percent of the field values in each field key that stores numerical values in the h2o_feet measurement.
The h2o_feet measurement has one numerical field: water_level.
Example 3: Select fifth percentile field value associated with each field key that matches a regular expression
> SELECT PERCENTILE(/level/,5) FROM "h2o_feet"
name: h2o_feet
time percentile_water_level
---- ----------------------
2015-08-31T03:42:00Z 1.122
The query returns the field value that is larger than five percent of the field values in each field key that stores numerical values and includes the word water in the h2o_feet measurement.
Example 4: Select the fifth percentile field values associated with a field key and the relevant tags and fields
> SELECT PERCENTILE("water_level",5),"location","level description" FROM "h2o_feet"
name: h2o_feet
time percentile location level description
---- ---------- -------- -----------------
2015-08-31T03:42:00Z 1.122 coyote_creek below 3 feet
The query returns the field value that is larger than five percent of the field values in the water_level field key and the relevant values of the location tag key and the level description field key.
Example 5: Select the twentieth percentile field value associated with a field key and include several clauses
> SELECT PERCENTILE("water_level",20) FROM "h2o_feet" WHERE time >= '2015-08-17T23:48:00Z' AND time <= '2015-08-18T00:54:00Z' GROUP BY time(24m) fill(15) LIMIT 2
name: h2o_feet
time percentile
---- ----------
2015-08-17T23:36:00Z 15
2015-08-18T00:00:00Z 2.064
The query returns the field value that is larger than 20 percent of the values in the water_level field key.
It covers the time range between 2015-08-17T23:48:00Z and 2015-08-18T00:54:00Z and groups results into 24-minute intervals.
It fills empty time intervals with 15 and it limits the number of points returned to two.
Notice that the GROUP BY time() clause overrides the points’ original timestamps.
The timestamps in the results indicate the the start of each 24-minute time interval; the first point in the results covers the time interval between 2015-08-17T23:36:00Z and just before 2015-08-18T00:00:00Z and the last point in the results covers the time interval between 2015-08-18T00:00:00Z and just before 2015-08-18T00:24:00Z.
Common Issues with PERCENTILE()
Issue 1: PERCENTILE() vs. other InfluxQL functions
PERCENTILE(<field_key>,100)is equivalent toMAX(<field_key>).PERCENTILE(<field_key>, 50)is nearly equivalent toMEDIAN(<field_key>), except theMEDIAN()function returns the average of the two middle values if the field key contains an even number of field values.PERCENTILE(<field_key>,0)is not equivalent toMIN(<field_key>). This is a known issue.
SAMPLE()
Returns a random sample of N field values.
SAMPLE() uses reservoir sampling to generate the random points.
Syntax
SELECT SAMPLE(<field_key>, <N>)[,<tag_key(s)>|<field_key(s)>] [INTO_clause] FROM_clause [WHERE_clause] [GROUP_BY_clause] [ORDER_BY_clause] [LIMIT_clause] [OFFSET_clause] [SLIMIT_clause] [SOFFSET_clause]
Description of Syntax
SAMPLE(field_key,N)
Returns N randomly selected field values associated with the field key.
SAMPLE(/regular_expression/,N)
Returns N randomly selected field values associated with each field key that matches the regular expression.
SAMPLE(*,N)
Returns N randomly selected field values associated with each field key in the measurement.
SAMPLE(field_key,N),tag_key(s),field_key(s)
Returns N randomly selected field values associated with the field key in the parentheses and the relevant tag and/or field.
N must be an integer.
SAMPLE() supports all field value data types.
Examples
Example 1: Select a sample of the field values associated with a field key
> SELECT SAMPLE("water_level",2) FROM "h2o_feet"
name: h2o_feet
time sample
---- ------
2015-09-09T21:48:00Z 5.659
2015-09-18T10:00:00Z 6.939
The query returns two randomly selected points from the water_level field key and in the h2o_feet measurement.
Example 2: Select a sample of the field values associated with each field key in a measurement
> SELECT SAMPLE(*,2) FROM "h2o_feet"
name: h2o_feet
time sample_level description sample_water_level
---- ------------------------ ------------------
2015-08-25T17:06:00Z 3.284
2015-09-03T04:30:00Z below 3 feet
2015-09-03T20:06:00Z between 3 and 6 feet
2015-09-08T21:54:00Z 3.412
The query returns two randomly selected points for each field key in the h2o_feet measurement.
The h2o_feet measurement has two field keys: level description and water_level.
Example 3: Select a sample of the field values associated with each field key that matches a regular expression
> SELECT SAMPLE(/level/,2) FROM "h2o_feet"
name: h2o_feet
time sample_level description sample_water_level
---- ------------------------ ------------------
2015-08-30T05:54:00Z between 6 and 9 feet
2015-09-07T01:18:00Z 7.854
2015-09-09T20:30:00Z 7.32
2015-09-13T19:18:00Z between 3 and 6 feet
The query returns two randomly selected points for each field key that includes the word level in the h2o_feet measurement.
Example 4: Select a sample of the field values associated with a field key and the relevant tags and fields
> SELECT SAMPLE("water_level",2),"location","level description" FROM "h2o_feet"
name: h2o_feet
time sample location level description
---- ------ -------- -----------------
2015-08-29T10:54:00Z 5.689 coyote_creek between 3 and 6 feet
2015-09-08T15:48:00Z 6.391 coyote_creek between 6 and 9 feet
The query returns two randomly selected points from the water_level field key and the relevant values of the location tag and the level description field.
Example 5: Select a sample of the field values associated with a field key and include several clauses
> SELECT SAMPLE("water_level",1) FROM "h2o_feet" WHERE time >= '2015-08-18T00:00:00Z' AND time <= '2015-08-18T00:30:00Z' AND "location" = 'santa_monica' GROUP BY time(18m)
name: h2o_feet
time sample
---- ------
2015-08-18T00:12:00Z 2.028
2015-08-18T00:30:00Z 2.051
The query returns one randomly selected point from the water_level field key.
It covers the time range between 2015-08-18T00:00:00Z and 2015-08-18T00:30:00Z and groups results into 18-minute intervals.
Notice that the GROUP BY time() clause does not override the points’ original timestamps.
See Issue 1 in the section below for a more detailed explanation of that behavior.
Common Issues with SAMPLE()
Issue 1: SAMPLE() with a GROUP BY time() clause
Queries with SAMPLE() and a GROUP BY time() clause return the specified
number of points (N) per GROUP BY time() interval.
For
most GROUP BY time() queries,
the returned timestamps mark the start of the GROUP BY time() interval.
GROUP BY time() queries with the SAMPLE() function behave differently;
they maintain the timestamp of the original data point.
Example
The query below returns two randomly selected points per 18-minute
GROUP BY time() interval.
Notice that the returned timestamps are the points’ original timestamps; they
are not forced to match the start of the GROUP BY time() intervals.
> SELECT SAMPLE("water_level",2) FROM "h2o_feet" WHERE time >= '2015-08-18T00:00:00Z' AND time <= '2015-08-18T00:30:00Z' AND "location" = 'santa_monica' GROUP BY time(18m)
name: h2o_feet
time sample
---- ------
__
2015-08-18T00:06:00Z 2.116 |
2015-08-18T00:12:00Z 2.028 | <------- Randomly-selected points for the first time interval
--
__
2015-08-18T00:18:00Z 2.126 |
2015-08-18T00:30:00Z 2.051 | <------- Randomly-selected points for the second time interval
--
TOP()
Returns the greatest N field values.
Syntax
SELECT TOP( <field_key>[,<tag_key(s)>],<N> )[,<tag_key(s)>|<field_key(s)>] [INTO_clause] FROM_clause [WHERE_clause] [GROUP_BY_clause] [ORDER_BY_clause] [LIMIT_clause] [OFFSET_clause] [SLIMIT_clause] [SOFFSET_clause]
Description of Syntax
TOP(field_key,N)
Returns the greatest N field values associated with the field key.
TOP(field_key,tag_key(s),N)
Returns the greatest field value for N tag values of the tag key.
TOP(field_key,N),tag_key(s),field_key(s)
Returns the greatest N field values associated with the field key in the parentheses and the relevant tag and/or field.
TOP() supports int64 and float64 field value data types.
Note:
TOP()returns the field value with the earliest timestamp if there’s a tie between two or more values for the greatest value.
Examples
Example 1: Select the top three field values associated with a field key
> SELECT TOP("water_level",3) FROM "h2o_feet"
name: h2o_feet
time top
---- ---
2015-08-29T07:18:00Z 9.957
2015-08-29T07:24:00Z 9.964
2015-08-29T07:30:00Z 9.954
The query returns the greatest three field values in the water_level field key and in the h2o_feet measurement.
Example 2: Select the top field value associated with a field key for two tags
> SELECT TOP("water_level","location",2) FROM "h2o_feet"
name: h2o_feet
time top location
---- --- --------
2015-08-29T03:54:00Z 7.205 santa_monica
2015-08-29T07:24:00Z 9.964 coyote_creek
The query returns the greatest field values in the water_level field key for two tag values associated with the location tag key.
Example 3: Select the top four field values associated with a field key and the relevant tags and fields
> SELECT TOP("water_level",4),"location","level description" FROM "h2o_feet"
name: h2o_feet
time top location level description
---- --- -------- -----------------
2015-08-29T07:18:00Z 9.957 coyote_creek at or greater than 9 feet
2015-08-29T07:24:00Z 9.964 coyote_creek at or greater than 9 feet
2015-08-29T07:30:00Z 9.954 coyote_creek at or greater than 9 feet
2015-08-29T07:36:00Z 9.941 coyote_creek at or greater than 9 feet
The query returns the greatest four field values in the water_level field key and the relevant values of the location tag key and the level description field key.
Example 4: Select the top three field values associated with a field key and include several clauses
> SELECT TOP("water_level",3),"location" FROM "h2o_feet" WHERE time >= '2015-08-18T00:00:00Z' AND time <= '2015-08-18T00:54:00Z' GROUP BY time(24m) ORDER BY time DESC
name: h2o_feet
time top location
---- --- --------
2015-08-18T00:48:00Z 7.11 coyote_creek
2015-08-18T00:48:00Z 6.982 coyote_creek
2015-08-18T00:48:00Z 2.054 santa_monica
2015-08-18T00:24:00Z 7.635 coyote_creek
2015-08-18T00:24:00Z 7.5 coyote_creek
2015-08-18T00:24:00Z 7.372 coyote_creek
2015-08-18T00:00:00Z 8.12 coyote_creek
2015-08-18T00:00:00Z 8.005 coyote_creek
2015-08-18T00:00:00Z 7.887 coyote_creek
The query returns the greatest three values in the water_level field key for each 24-minute interval between 2015-08-18T00:00:00Z and 2015-08-18T00:54:00Z.
It also returns results in descending timestamp order.
Notice that the GROUP BY time() clause overrides the points’ original timestamps.
The timestamps in the results indicate the the start of each 24-minute time interval;
the last three points in the results are for the time interval between 2015-08-18T00:00:00Z and just before 2015-08-18T00:24:00Z.
Common Issues with TOP()
Issue 1: TOP(), the INTO clause, and the GROUP BY time() clause
Using the TOP() function with the INTO clause
and the GROUP BY time() clause can cause InfluxDB to overwrite points in the destination measurement.
Using TOP() with the GROUP BY time() clause often returns several results with the same timestamp; InfluxDB assumes points with the same series and timestamp are duplicate points and simply overwrites any duplicate point with the most recent point in the destination measurement.
Example
The first query in the codeblock below uses the TOP() function with a GROUP BY time() clause, and it returns four results.
Notice that the first two results have the same timestamp and the last two results have the same timestamp.
The second query adds an INTO clause to the initial query and writes the query results to the top_dweller measurement.
The last query in the codeblock selects all the data in the top_dweller measurement.
The last query returns two points instead of four points, because two of the initial results are duplicate points; they belong to the same series and have the same timestamp. When the system encounters duplicate points, it simply overwrites the previous point with the most recent point.
> SELECT TOP("water_level",2),"location" FROM "h2o_feet" WHERE time >= '2015-08-18T00:00:00Z' AND time <= '2015-08-18T00:24:00Z' GROUP BY time(24m)
name: h2o_feet
time top location
---- --- --------
2015-08-18T00:00:00Z 8.12 coyote_creek
2015-08-18T00:00:00Z 8.005 coyote_creek
2015-08-18T00:24:00Z 7.635 coyote_creek
2015-08-18T00:24:00Z 2.041 santa_monica
> SELECT TOP("water_level",2),"location" INTO "top_dweller" FROM "h2o_feet" WHERE time >= '2015-08-18T00:00:00Z' AND time <= '2015-08-18T00:24:00Z' GROUP BY time(24m)
name: result
time written
---- -------
1970-01-01T00:00:00Z 4
> SELECT * FROM "top_dweller"
name: top_dweller
time location top
---- -------- ---
2015-08-18T00:00:00Z coyote_creek 8.005
2015-08-18T00:24:00Z santa_monica 2.041
Issue 2: TOP() and a tag key with fewer than N tag values
Queries with the syntax SELECT TOP(<field_key>,<tag_key>,<N>) can return fewer points than expected.
If the tag key has X tag values, the query specifies N values, and X is smaller than N, then the query returns X points.
Example
The query below asks for the greatest field values of water_level for three tag values of the location tag key.
Because the location tag key has two tag values (santa_monica and coyote_creek), the query returns two points instead of three.
> SELECT TOP("water_level","location",3) FROM "h2o_feet"
name: h2o_feet
time top location
---- --- --------
2015-08-29T03:54:00Z 7.205 santa_monica
2015-08-29T07:24:00Z 9.964 coyote_creek
Transformations
CEILING()
CEILING() is not yet functional.
See GitHub Issue #5930 for more information.
CUMULATIVE_SUM()
Returns the running total of subsequent field values.
Basic Syntax
SELECT CUMULATIVE_SUM( [ * | <field_key> | /<regular_expression>/ ] ) [INTO_clause] FROM_clause [WHERE_clause] [GROUP_BY_clause] [ORDER_BY_clause] [LIMIT_clause] [OFFSET_clause] [SLIMIT_clause] [SOFFSET_clause]
Description of Basic Syntax
CUMULATIVE_SUM(field_key)
Returns the running total of subsequent field values associated with the field key.
CUMULATIVE_SUM(/regular_expression/)
Returns the running total of subsequent field values associated with each field key that matches the regular expression.
CUMULATIVE_SUM(*)
Returns the running total of subsequent field values associated with each field key in the measurement.
CUMULATIVE_SUM() supports int64 and float64 field value data types.
The basic syntax supports GROUP BY clauses that group by tags but not GROUP BY clauses that group by time.
See the Advanced Syntax section for how to use CUMULATIVE_SUM() with a GROUP BY time() clause.
Examples of Basic Syntax
Examples 1-4 use the following subsample of the NOAA_water_database data:
> SELECT "water_level" FROM "h2o_feet" WHERE time >= '2015-08-18T00:00:00Z' AND time <= '2015-08-18T00:30:00Z' AND "location" = 'santa_monica'
name: h2o_feet
time water_level
---- -----------
2015-08-18T00:00:00Z 2.064
2015-08-18T00:06:00Z 2.116
2015-08-18T00:12:00Z 2.028
2015-08-18T00:18:00Z 2.126
2015-08-18T00:24:00Z 2.041
2015-08-18T00:30:00Z 2.051
Example 1: Calculate the cumulative sum of the field values associated with a field key
> SELECT CUMULATIVE_SUM("water_level") FROM "h2o_feet" WHERE time >= '2015-08-18T00:00:00Z' AND time <= '2015-08-18T00:30:00Z' AND "location" = 'santa_monica'
name: h2o_feet
time cumulative_sum
---- --------------
2015-08-18T00:00:00Z 2.064
2015-08-18T00:06:00Z 4.18
2015-08-18T00:12:00Z 6.208
2015-08-18T00:18:00Z 8.334
2015-08-18T00:24:00Z 10.375
2015-08-18T00:30:00Z 12.426
The query returns the running total of the field values in the water_level field key and in the h2o_feet measurement.
Example 2: Calculate the cumulative sum of the field values associated with each field key in a measurement
> SELECT CUMULATIVE_SUM(*) FROM "h2o_feet" WHERE time >= '2015-08-18T00:00:00Z' AND time <= '2015-08-18T00:30:00Z' AND "location" = 'santa_monica'
name: h2o_feet
time cumulative_sum_water_level
---- --------------------------
2015-08-18T00:00:00Z 2.064
2015-08-18T00:06:00Z 4.18
2015-08-18T00:12:00Z 6.208
2015-08-18T00:18:00Z 8.334
2015-08-18T00:24:00Z 10.375
2015-08-18T00:30:00Z 12.426
The query returns the running total of the field values for each field key that stores numerical values in the h2o_feet measurement.
The h2o_feet measurement has one numerical field: water_level.
Example 3: Calculate the cumulative sum of the field values associated with each field key that matches a regular expression
> SELECT CUMULATIVE_SUM(/water/) FROM "h2o_feet" WHERE time >= '2015-08-18T00:00:00Z' AND time <= '2015-08-18T00:30:00Z' AND "location" = 'santa_monica'
name: h2o_feet
time cumulative_sum_water_level
---- --------------------------
2015-08-18T00:00:00Z 2.064
2015-08-18T00:06:00Z 4.18
2015-08-18T00:12:00Z 6.208
2015-08-18T00:18:00Z 8.334
2015-08-18T00:24:00Z 10.375
2015-08-18T00:30:00Z 12.426
The query returns the running total of the field values for each field key that stores numerical values and includes the word water in the h2o_feet measurement.
Example 4: Calculate the cumulative sum of the field values associated with a field key and include several clauses
> SELECT CUMULATIVE_SUM("water_level") FROM "h2o_feet" WHERE time >= '2015-08-18T00:00:00Z' AND time <= '2015-08-18T00:30:00Z' AND "location" = 'santa_monica' ORDER BY time DESC LIMIT 4 OFFSET 2
name: h2o_feet
time cumulative_sum
---- --------------
2015-08-18T00:18:00Z 6.218
2015-08-18T00:12:00Z 8.246
2015-08-18T00:06:00Z 10.362
2015-08-18T00:00:00Z 12.426
The query returns the running total of the field values associated with the water_level field key.
It covers the time range between 2015-08-18T00:00:00Z and 2015-08-18T00:30:00Z and returns results in descending timestamp order.
The query also limits the number of points returned to four and offsets results by two points.
Advanced Syntax
SELECT CUMULATIVE_SUM(<function>( [ * | <field_key> | /<regular_expression>/ ] )) [INTO_clause] FROM_clause [WHERE_clause] GROUP_BY_clause [ORDER_BY_clause] [LIMIT_clause] [OFFSET_clause] [SLIMIT_clause] [SOFFSET_clause]
Description of Advanced Syntax
The advanced syntax requires a GROUP BY time() clause and a nested InfluxQL function.
The query first calculates the results for the nested function at the specified GROUP BY time() interval and then applies the CUMULATIVE_SUM() function to those results.
CUMULATIVE_SUM() supports the following nested functions:
COUNT(),
MEAN(),
MEDIAN(),
MODE(),
SUM(),
FIRST(),
LAST(),
MIN(),
MAX(), and
PERCENTILE().
Examples of Advanced Syntax
Example 1: Calculate the cumulative sum of mean values
> SELECT CUMULATIVE_SUM(MEAN("water_level")) FROM "h2o_feet" WHERE time >= '2015-08-18T00:00:00Z' AND time <= '2015-08-18T00:30:00Z' AND "location" = 'santa_monica' GROUP BY time(12m)
name: h2o_feet
time cumulative_sum
---- --------------
2015-08-18T00:00:00Z 2.09
2015-08-18T00:12:00Z 4.167
2015-08-18T00:24:00Z 6.213
The query returns the running total of average water_levels that are calculated at 12-minute intervals.
To get those results, InfluxDB first calculates the average water_levels at 12-minute intervals.
This step is the same as using the MEAN() function with the GROUP BY time() clause and without CUMULATIVE_SUM():
> SELECT MEAN("water_level") FROM "h2o_feet" WHERE time >= '2015-08-18T00:00:00Z' AND time <= '2015-08-18T00:30:00Z' AND "location" = 'santa_monica' GROUP BY time(12m)
name: h2o_feet
time mean
---- ----
2015-08-18T00:00:00Z 2.09
2015-08-18T00:12:00Z 2.077
2015-08-18T00:24:00Z 2.0460000000000003
Next, InfluxDB calculates the running total of those averages.
The second point in the final results (4.167) is the sum of 2.09 and 2.077
and the third point (6.213) is the sum of 2.09, 2.077, and 2.0460000000000003.
DERIVATIVE()
Returns the rate of change between subsequent field values.
Basic Syntax
SELECT DERIVATIVE( [ * | <field_key> | /<regular_expression>/ ] [ , <unit> ] ) [INTO_clause] FROM_clause [WHERE_clause] [GROUP_BY_clause] [ORDER_BY_clause] [LIMIT_clause] [OFFSET_clause] [SLIMIT_clause] [SOFFSET_clause]
Description of Basic Syntax
InfluxDB calculates the difference between subsequent field values and converts those results into the rate of change per unit.
The unit argument is an integer followed by a duration literal and it is optional.
If the query does not specify the unit the unit defaults to one second (1s).
DERIVATIVE(field_key)
Returns the rate of change between subsequent field values associated with the field key.
DERIVATIVE(/regular_expression/)
Returns the rate of change between subsequent field values associated with each field key that matches the regular expression.
DERIVATIVE(*)
Returns the rate of change between subsequent field values associated with each field key in the measurement.
DERIVATIVE() supports int64 and float64 field value data types.
The basic syntax supports GROUP BY clauses that group by tags but not GROUP BY clauses that group by time.
See the Advanced Syntax section for how to use DERIVATIVE() with a GROUP BY time() clause.
Examples of Basic Syntax
Examples 1-5 use the following subsample of the NOAA_water_database data:
> SELECT "water_level" FROM "h2o_feet" WHERE "location" = 'santa_monica' AND time >= '2015-08-18T00:00:00Z' AND time <= '2015-08-18T00:30:00Z'
name: h2o_feet
time water_level
---- -----------
2015-08-18T00:00:00Z 2.064
2015-08-18T00:06:00Z 2.116
2015-08-18T00:12:00Z 2.028
2015-08-18T00:18:00Z 2.126
2015-08-18T00:24:00Z 2.041
2015-08-18T00:30:00Z 2.051
Example 1: Calculate the derivative between the field values associated with a field key
> SELECT DERIVATIVE("water_level") FROM "h2o_feet" WHERE "location" = 'santa_monica' AND time >= '2015-08-18T00:00:00Z' AND time <= '2015-08-18T00:30:00Z'
name: h2o_feet
time derivative
---- ----------
2015-08-18T00:06:00Z 0.00014444444444444457
2015-08-18T00:12:00Z -0.00024444444444444465
2015-08-18T00:18:00Z 0.0002722222222222218
2015-08-18T00:24:00Z -0.000236111111111111
2015-08-18T00:30:00Z 2.777777777777842e-05
The query returns the one-second rate of change between the field values associated with the water_level field key and in the h2o_feet measurement.
The first result (0.00014444444444444457) is the one-second rate of change between the first two subsequent field values in the raw data.
InfluxDB calculates the difference between the field values and normalizes that value to the one-second rate of change:
(2.116 - 2.064) / (360s / 1s)
-------------- ----------
| |
| the difference between the field values' timestamps / the default unit
second field value - first field value
Example 2: Calculate the derivative between the field values associated with a field key and specify the unit option
> SELECT DERIVATIVE("water_level",6m) FROM "h2o_feet" WHERE "location" = 'santa_monica' AND time >= '2015-08-18T00:00:00Z' AND time <= '2015-08-18T00:30:00Z'
name: h2o_feet
time derivative
---- ----------
2015-08-18T00:06:00Z 0.052000000000000046
2015-08-18T00:12:00Z -0.08800000000000008
2015-08-18T00:18:00Z 0.09799999999999986
2015-08-18T00:24:00Z -0.08499999999999996
2015-08-18T00:30:00Z 0.010000000000000231
The query returns the six-minute rate of change between the field values associated with the water_level field key and in the h2o_feet measurement.
The first result (0.052000000000000046) is the six-minute rate of change between the first two subsequent field values in the raw data.
InfluxDB calculates the difference between the field values and normalizes that value to the six-minute rate of change:
(2.116 - 2.064) / (6m / 6m)
-------------- ----------
| |
| the difference between the field values' timestamps / the specified unit
second field value - first field value
Example 3: Calculate the derivative between the field values associated with each field key in a measurement and specify the unit option
> SELECT DERIVATIVE(*,3m) FROM "h2o_feet" WHERE "location" = 'santa_monica' AND time >= '2015-08-18T00:00:00Z' AND time <= '2015-08-18T00:30:00Z'
name: h2o_feet
time derivative_water_level
---- ----------------------
2015-08-18T00:06:00Z 0.026000000000000023
2015-08-18T00:12:00Z -0.04400000000000004
2015-08-18T00:18:00Z 0.04899999999999993
2015-08-18T00:24:00Z -0.04249999999999998
2015-08-18T00:30:00Z 0.0050000000000001155
The query returns the three-minute rate of change between the field values associated with each field key that stores numerical values in the h2o_feet measurement.
The h2o_feet measurement has one numerical field: water_level.
The first result (0.026000000000000023) is the three-minute rate of change between the first two subsequent field values in the raw data.
InfluxDB calculates the difference between the field values and normalizes that value to the three-minute rate of change:
(2.116 - 2.064) / (6m / 3m)
-------------- ----------
| |
| the difference between the field values' timestamps / the specified unit
second field value - first field value
Example 4: Calculate the derivative between the field values associated with each field key that matches a regular expression and specify the unit option
> SELECT DERIVATIVE(/water/,2m) FROM "h2o_feet" WHERE "location" = 'santa_monica' AND time >= '2015-08-18T00:00:00Z' AND time <= '2015-08-18T00:30:00Z'
name: h2o_feet
time derivative_water_level
---- ----------------------
2015-08-18T00:06:00Z 0.01733333333333335
2015-08-18T00:12:00Z -0.02933333333333336
2015-08-18T00:18:00Z 0.03266666666666662
2015-08-18T00:24:00Z -0.02833333333333332
2015-08-18T00:30:00Z 0.0033333333333334103
The query returns the two-minute rate of change between the field values associated with each field key that stores numerical values and includes the word water in the h2o_feet measurement.
The first result (0.01733333333333335) is the two-minute rate of change between the first two subsequent field values in the raw data.
InfluxDB calculates the difference between the field values and normalizes that value to the two-minute rate of change:
(2.116 - 2.064) / (6m / 2m)
-------------- ----------
| |
| the difference between the field values' timestamps / the specified unit
second field value - first field value
Example 5: Calculate the derivative between the field values associated with a field key and include several clauses
> SELECT DERIVATIVE("water_level") FROM "h2o_feet" WHERE "location" = 'santa_monica' AND time >= '2015-08-18T00:00:00Z' AND time <= '2015-08-18T00:30:00Z' ORDER BY time DESC LIMIT 1 OFFSET 2
name: h2o_feet
time derivative
---- ----------
2015-08-18T00:12:00Z -0.0002722222222222218
The query returns the one-second rate of change between the field values associated with the water_level field key and in the h2o_feet measurement.
It covers the time range between 2015-08-18T00:00:00Z and 2015-08-18T00:30:00Z and returns results in descending timestamp order.
The query also limits the number of points returned to one and offsets results by two points.
The only result (-0.0002722222222222218) is the one-second rate of change between the relevant subsequent field values in the raw data.
InfluxDB calculates the difference between the field values and normalizes that value to the one-second rate of change:
(2.126 - 2.028) / (360s / 1s)
-------------- ----------
| |
| the difference between the field values' timestamps / the default unit
second field value - first field value
Advanced Syntax
SELECT DERIVATIVE(<function> ([ * | <field_key> | /<regular_expression>/ ]) [ , <unit> ] ) [INTO_clause] FROM_clause [WHERE_clause] GROUP_BY_clause [ORDER_BY_clause] [LIMIT_clause] [OFFSET_clause] [SLIMIT_clause] [SOFFSET_clause]
Description of Advanced Syntax
The advanced syntax requires a GROUP BY time() clause and a nested InfluxQL function.
The query first calculates the results for the nested function at the specified GROUP BY time() interval and then applies the DERIVATIVE() function to those results.
The unit argument is an integer followed by a duration literal and it is optional.
If the query does not specify the unit the unit defaults to the GROUP BY time() interval.
Note that this behavior is different from the basic syntax’s default behavior.
DERIVATIVE() supports the following nested functions:
COUNT(),
MEAN(),
MEDIAN(),
MODE(),
SUM(),
FIRST(),
LAST(),
MIN(),
MAX(), and
PERCENTILE().
Examples of Advanced Syntax
Example 1: Calculate the derivative of mean values
> SELECT DERIVATIVE(MEAN("water_level")) FROM "h2o_feet" WHERE "location" = 'santa_monica' AND time >= '2015-08-18T00:00:00Z' AND time <= '2015-08-18T00:30:00Z' GROUP BY time(12m)
name: h2o_feet
time derivative
---- ----------
2015-08-18T00:12:00Z -0.0129999999999999
2015-08-18T00:24:00Z -0.030999999999999694
The query returns the 12-minute rate of change between average water_levels that are calculated at 12-minute intervals.
To get those results, InfluxDB first calculates the average water_levels at 12-minute intervals.
This step is the same as using the MEAN() function with the GROUP BY time() clause and without DERIVATIVE():
> SELECT MEAN("water_level") FROM "h2o_feet" WHERE "location" = 'santa_monica' AND time >= '2015-08-18T00:00:00Z' AND time <= '2015-08-18T00:30:00Z' GROUP BY time(12m)
name: h2o_feet
time mean
---- ----
2015-08-18T00:00:00Z 2.09
2015-08-18T00:12:00Z 2.077
2015-08-18T00:24:00Z 2.0460000000000003
Next, InfluxDB calculates the 12-minute rate of change between those averages.
The first result (-0.0129999999999999) is the 12-minute rate of change between the first two averages.
InfluxDB calculates the difference between the field values and normalizes that value to the 12-minute rate of change.
(2.077 - 2.09) / (12m / 12m)
------------- ----------
| |
| the difference between the field values' timestamps / the default unit
second field value - first field value
Example 2: Calculate the derivative of mean values and specify the unit option
> SELECT DERIVATIVE(MEAN("water_level"),6m) FROM "h2o_feet" WHERE "location" = 'santa_monica' AND time >= '2015-08-18T00:00:00Z' AND time <= '2015-08-18T00:30:00Z' GROUP BY time(12m)
name: h2o_feet
time derivative
---- ----------
2015-08-18T00:12:00Z -0.00649999999999995
2015-08-18T00:24:00Z -0.015499999999999847
The query returns the six-minute rate of change between average water_levels that are calculated at 12-minute intervals.
To get those results, InfluxDB first calculates the average water_levels at 12-minute intervals.
This step is the same as using the MEAN() function with the GROUP BY time() clause and without DERIVATIVE():
> SELECT MEAN("water_level") FROM "h2o_feet" WHERE "location" = 'santa_monica' AND time >= '2015-08-18T00:00:00Z' AND time <= '2015-08-18T00:30:00Z' GROUP BY time(12m)
name: h2o_feet
time mean
---- ----
2015-08-18T00:00:00Z 2.09
2015-08-18T00:12:00Z 2.077
2015-08-18T00:24:00Z 2.0460000000000003
Next, InfluxDB calculates the six-minute rate of change between those averages.
The first result (-0.00649999999999995) is the six-minute rate of change between the first two averages.
InfluxDB calculates the difference between the field values and normalizes that value to the six-minute rate of change.
(2.077 - 2.09) / (12m / 6m)
------------- ----------
| |
| the difference between the field values' timestamps / the specified unit
second field value - first field value
DIFFERENCE()
Returns the result of subtraction between subsequent field values.
Basic Syntax
SELECT DIFFERENCE( [ * | <field_key> | /<regular_expression>/ ] ) [INTO_clause] FROM_clause [WHERE_clause] [GROUP_BY_clause] [ORDER_BY_clause] [LIMIT_clause] [OFFSET_clause] [SLIMIT_clause] [SOFFSET_clause]
Description of Basic Syntax
DIFFERENCE(field_key)
Returns the difference between subsequent field values associated with the field key.
DIFFERENCE(/regular_expression/)
Returns the difference between subsequent field values associated with each field key that matches the regular expression.
DIFFERENCE(*)
Returns the difference between subsequent field values associated with each field key in the measurement.
DIFFERENCE() supports int64 and float64 field value data types.
The basic syntax supports GROUP BY clauses that group by tags but not GROUP BY clauses that group by time.
See the Advanced Syntax section for how to use DIFFERENCE() with a GROUP BY time() clause.
Examples of Basic Syntax
Examples 1-4 use the following subsample of the NOAA_water_database data:
> SELECT "water_level" FROM "h2o_feet" WHERE time >= '2015-08-18T00:00:00Z' AND time <= '2015-08-18T00:30:00Z' AND "location" = 'santa_monica'
name: h2o_feet
time water_level
---- -----------
2015-08-18T00:00:00Z 2.064
2015-08-18T00:06:00Z 2.116
2015-08-18T00:12:00Z 2.028
2015-08-18T00:18:00Z 2.126
2015-08-18T00:24:00Z 2.041
2015-08-18T00:30:00Z 2.051
Example 1: Calculate the difference between the field values associated with a field key
> SELECT DIFFERENCE("water_level") FROM "h2o_feet" WHERE time >= '2015-08-18T00:00:00Z' AND time <= '2015-08-18T00:30:00Z' AND "location" = 'santa_monica'
name: h2o_feet
time difference
---- ----------
2015-08-18T00:06:00Z 0.052000000000000046
2015-08-18T00:12:00Z -0.08800000000000008
2015-08-18T00:18:00Z 0.09799999999999986
2015-08-18T00:24:00Z -0.08499999999999996
2015-08-18T00:30:00Z 0.010000000000000231
The query returns the difference between the subsequent field values in the water_level field key and in the h2o_feet measurement.
Example 2: Calculate the difference between the field values associated with each field key in a measurement
> SELECT DIFFERENCE(*) FROM "h2o_feet" WHERE time >= '2015-08-18T00:00:00Z' AND time <= '2015-08-18T00:30:00Z' AND "location" = 'santa_monica'
name: h2o_feet
time difference_water_level
---- ----------------------
2015-08-18T00:06:00Z 0.052000000000000046
2015-08-18T00:12:00Z -0.08800000000000008
2015-08-18T00:18:00Z 0.09799999999999986
2015-08-18T00:24:00Z -0.08499999999999996
2015-08-18T00:30:00Z 0.010000000000000231
The query returns the difference between the subsequent field values for each field key that stores numerical values in the h2o_feet measurement.
The h2o_feet measurement has one numerical field: water_level.
Example 3: Calculate the difference between the field values associated with each field key that matches a regular expression
> SELECT DIFFERENCE(/water/) FROM "h2o_feet" WHERE time >= '2015-08-18T00:00:00Z' AND time <= '2015-08-18T00:30:00Z' AND "location" = 'santa_monica'
name: h2o_feet
time difference_water_level
---- ----------------------
2015-08-18T00:06:00Z 0.052000000000000046
2015-08-18T00:12:00Z -0.08800000000000008
2015-08-18T00:18:00Z 0.09799999999999986
2015-08-18T00:24:00Z -0.08499999999999996
2015-08-18T00:30:00Z 0.010000000000000231
The query returns the difference between the subsequent field values for each field key that stores numerical values and includes the word water in the h2o_feet measurement.
Example 4: Calculate the difference between the field values associated with a field key and include several clauses
> SELECT DIFFERENCE("water_level") FROM "h2o_feet" WHERE time >= '2015-08-18T00:00:00Z' AND time <= '2015-08-18T00:30:00Z' AND "location" = 'santa_monica' ORDER BY time DESC LIMIT 2 OFFSET 2
name: h2o_feet
time difference
---- ----------
2015-08-18T00:12:00Z -0.09799999999999986
2015-08-18T00:06:00Z 0.08800000000000008
The query returns the difference between the subsequent field values in the water_level field key.
It covers the time range between 2015-08-18T00:00:00Z and 2015-08-18T00:30:00Z and returns results in descending timestamp order.
They query also limits the number of points returned to two and offsets results by two points.
Advanced Syntax
SELECT DIFFERENCE(<function>( [ * | <field_key> | /<regular_expression>/ ] )) [INTO_clause] FROM_clause [WHERE_clause] GROUP_BY_clause [ORDER_BY_clause] [LIMIT_clause] [OFFSET_clause] [SLIMIT_clause] [SOFFSET_clause]
Description of Advanced Syntax
The advanced syntax requires a GROUP BY time() clause and a nested InfluxQL function.
The query first calculates the results for the nested function at the specified GROUP BY time() interval and then applies the DIFFERENCE() function to those results.
DIFFERENCE() supports the following nested functions:
COUNT(),
MEAN(),
MEDIAN(),
MODE(),
SUM(),
FIRST(),
LAST(),
MIN(),
MAX(), and
PERCENTILE().
Examples of Advanced Syntax
Example 1: Calculate the difference between maximum values
> SELECT DIFFERENCE(MAX("water_level")) FROM "h2o_feet" WHERE time >= '2015-08-18T00:00:00Z' AND time <= '2015-08-18T00:30:00Z' AND "location" = 'santa_monica' GROUP BY time(12m)
name: h2o_feet
time difference
---- ----------
2015-08-18T00:12:00Z 0.009999999999999787
2015-08-18T00:24:00Z -0.07499999999999973
The query returns the difference between maximum water_levels that are calculated at 12-minute intervals.
To get those results, InfluxDB first calculates the maximum water_levels at 12-minute intervals.
This step is the same as using the MAX() function with the GROUP BY time() clause and without DIFFERENCE():
> SELECT MAX("water_level") FROM "h2o_feet" WHERE time >= '2015-08-18T00:00:00Z' AND time <= '2015-08-18T00:30:00Z' AND "location" = 'santa_monica' GROUP BY time(12m)
name: h2o_feet
time max
---- ---
2015-08-18T00:00:00Z 2.116
2015-08-18T00:12:00Z 2.126
2015-08-18T00:24:00Z 2.051
Next, InfluxDB calculates the difference between those maximum values.
The first point in the final results (0.009999999999999787) is the difference between 2.126 and 2.116, and the second point in the final results (-0.07499999999999973) is the difference between 2.051 and 2.126.
ELAPSED()
Returns the difference between subsequent field value’s timestamps.
Syntax
SELECT ELAPSED( [ * | <field_key> | /<regular_expression>/ ] [ , <unit> ] ) [INTO_clause] FROM_clause [WHERE_clause] [GROUP_BY_clause] [ORDER_BY_clause] [LIMIT_clause] [OFFSET_clause] [SLIMIT_clause] [SOFFSET_clause]
Description of Syntax
InfluxDB calculates the difference between subsequent timestamps.
The unit option is an integer followed by a duration literal and it determines the unit of the returned difference.
If the query does not specify the unit option the query returns the difference between timestamps in nanoseconds.
ELAPSED(field_key)
Returns the difference between subsequent timestamps associated with the field key.
ELAPSED(/regular_expression/)
Returns the difference between subsequent timestamps associated with each field key that matches the regular expression.
ELAPSED(*)
Returns the difference between subsequent timestamps associated with each field key in the measurement.
ELAPSED() supports all field value data types.
Examples
Examples 1-5 use the following subsample of the NOAA_water_database data:
> SELECT "water_level" FROM "h2o_feet" WHERE "location" = 'santa_monica' AND time >= '2015-08-18T00:00:00Z' AND time <= '2015-08-18T00:12:00Z'
name: h2o_feet
time water_level
---- -----------
2015-08-18T00:00:00Z 2.064
2015-08-18T00:06:00Z 2.116
2015-08-18T00:12:00Z 2.028
Example 1: Calculate the elapsed time between field values associated with a field key
> SELECT ELAPSED("water_level") FROM "h2o_feet" WHERE "location" = 'santa_monica' AND time >= '2015-08-18T00:00:00Z' AND time <= '2015-08-18T00:12:00Z'
name: h2o_feet
time elapsed
---- -------
2015-08-18T00:06:00Z 360000000000
2015-08-18T00:12:00Z 360000000000
The query returns the difference (in nanoseconds) between subsequent timestamps in the water_level field key and in the h2o_feet measurement.
Example 2: Calculate the elapsed time between field values associated with a field key and specify the unit option
> SELECT ELAPSED("water_level",1m) FROM "h2o_feet" WHERE "location" = 'santa_monica' AND time >= '2015-08-18T00:00:00Z' AND time <= '2015-08-18T00:12:00Z'
name: h2o_feet
time elapsed
---- -------
2015-08-18T00:06:00Z 6
2015-08-18T00:12:00Z 6
The query returns the difference (in minutes) between subsequent timestamps in the water_level field key and in the h2o_feet measurement.
Example 3: Calculate the elapsed time between field values associated with each field key in a measurement and specify the unit option
> SELECT ELAPSED(*,1m) FROM "h2o_feet" WHERE "location" = 'santa_monica' AND time >= '2015-08-18T00:00:00Z' AND time <= '2015-08-18T00:12:00Z'
name: h2o_feet
time elapsed_level description elapsed_water_level
---- ------------------------- -------------------
2015-08-18T00:06:00Z 6 6
2015-08-18T00:12:00Z 6 6
The query returns the difference (in minutes) between subsequent timestamps associated with each field key in the h2o_feet
measurement.
The h2o_feet measurement has two field keys: level description and water_level.
Example 4: Calculate the elapsed time between field values associated with each field key that matches a regular expression and specify the unit option
> SELECT ELAPSED(/level/,1s) FROM "h2o_feet" WHERE "location" = 'santa_monica' AND time >= '2015-08-18T00:00:00Z' AND time <= '2015-08-18T00:12:00Z'
name: h2o_feet
time elapsed_level description elapsed_water_level
---- ------------------------- -------------------
2015-08-18T00:06:00Z 360 360
2015-08-18T00:12:00Z 360 360
The query returns the difference (in seconds) between subsequent timestamps associated with each field key that includes the word level in the h2o_feet measurement.
Example 5: Calculate the elapsed time between field values associated with a field key and include several clauses
> SELECT ELAPSED("water_level",1ms) FROM "h2o_feet" WHERE "location" = 'santa_monica' AND time >= '2015-08-18T00:00:00Z' AND time <= '2015-08-18T00:12:00Z' ORDER BY time DESC LIMIT 1 OFFSET 1
name: h2o_feet
time elapsed
---- -------
2015-08-18T00:00:00Z -360000
The query returns the difference (in milliseconds) between subsequent timestamps in the water_level field key and in the h2o_feet measurement.
It covers the time range between 2015-08-18T00:00:00Z and 2015-08-18T00:12:00Z and sorts timestamps in descending order.
The query also limits the number of points returned to one and offsets results by one point.
Notice that the result is negative; the ORDER BY time DESC clause sorts timestamps in descending order so ELAPSED() calculates the difference between timestamps in reverse order.
Common Issues with ELAPSED()
Issue 1: ELAPSED() and units greater than the elapsed time
InfluxDB returns 0 if the unit option is greater than the difference between the timestamps.
Example
The timestamps in the h2o_feet measurement occur at six-minute intervals.
If the query sets the unit option to one hour, InfluxDB returns 0:
> SELECT ELAPSED("water_level",1h) FROM "h2o_feet" WHERE "location" = 'santa_monica' AND time >= '2015-08-18T00:00:00Z' AND time <= '2015-08-18T00:12:00Z'
name: h2o_feet
time elapsed
---- -------
2015-08-18T00:06:00Z 0
2015-08-18T00:12:00Z 0
Issue 2: ELAPSED() with GROUP BY time() clauses
The ELAPSED() function supports the GROUP BY time() clause but the query results aren’t particularly useful.
Currently, an ELAPSED() query with a nested function and a GROUP BY time() clause simply returns the interval specified in the GROUP BY time() clause.
The GROUP BY time() clause determines the timestamps in the results; each timestamp marks the start of a time interval.
That behavior also applies to nested selector functions (like FIRST() or MAX()) which would, in all other cases, return a specific timestamp from the raw data.
Because the GROUP BY time() clause overrides the original timestamps, the ELAPSED() calculation always returns the same value as the GROUP BY time() interval.
Example
In the codeblock below, the first query attempts to use the ELAPSED() function with a GROUP BY time() clause to find the time elapsed (in minutes) between minimum water_levels.
The query returns 12 minutes for both time intervals.
To get those results, InfluxDB first calculates the minimum water_levels at 12-minute intervals.
The second query in the codeblock shows the results of that step.
The step is the same as using the MIN() function with the GROUP BY time() clause and without the ELAPSED() function.
Notice that the timestamps returned by the second query are 12 minutes apart.
In the raw data, the first result (2.057) occurs at 2015-08-18T00:42:00Z but the GROUP BY time() clause overrides that original timestamp.
Because the timestamps are determined by the GROUP BY time() interval and not by the original data, the ELAPSED() calculation always returns the same value as the GROUP BY time() interval.
> SELECT ELAPSED(MIN("water_level"),1m) FROM "h2o_feet" WHERE "location" = 'santa_monica' AND time >= '2015-08-18T00:36:00Z' AND time <= '2015-08-18T00:54:00Z' GROUP BY time(12m)
name: h2o_feet
time elapsed
---- -------
2015-08-18T00:36:00Z 12
2015-08-18T00:48:00Z 12
> SELECT MIN("water_level") FROM "h2o_feet" WHERE "location" = 'santa_monica' AND time >= '2015-08-18T00:36:00Z' AND time <= '2015-08-18T00:54:00Z' GROUP BY time(12m)
name: h2o_feet
time min
---- ---
2015-08-18T00:36:00Z 2.057 <--- Actually occurs at 2015-08-18T00:42:00Z
2015-08-18T00:48:00Z 1.991
FLOOR()
FLOOR() is not yet functional.
See GitHub Issue #5930 for more information.
HISTOGRAM()
HISTOGRAM() is not yet functional.
See GitHub Issue #5930 for more information.
MOVING_AVERAGE()
Returns the rolling average across a window of subsequent field values.
Basic Syntax
SELECT MOVING_AVERAGE( [ * | <field_key> | /<regular_expression>/ ] , <N> ) [INTO_clause] FROM_clause [WHERE_clause] [GROUP_BY_clause] [ORDER_BY_clause] [LIMIT_clause] [OFFSET_clause] [SLIMIT_clause] [SOFFSET_clause]
Description of Basic Syntax
MOVING_AVERAGE() calculates the rolling average across a window of N subsequent field values.
The N argument is an integer and it is required.
MOVING_AVERAGE(field_key,N)
Returns the rolling average across N field values associated with the field key.
MOVING_AVERAGE(/regular_expression/,N)
Returns the rolling average across N field values associated with each field key that matches the regular expression.
MOVING_AVERAGE(*,N)
Returns the rolling average across N field values associated with each field key in the measurement.
MOVING_AVERAGE() int64 and float64 field value data types.
The basic syntax supports GROUP BY clauses that group by tags but not GROUP BY clauses that group by time.
See the Advanced Syntax section for how to use MOVING_AVERAGE() with a GROUP BY time() clause.
Examples of Basic Syntax
Examples 1-4 use the following subsample of the NOAA_water_database data:
> SELECT "water_level" FROM "h2o_feet" WHERE "location" = 'santa_monica' AND time >= '2015-08-18T00:00:00Z' AND time <= '2015-08-18T00:30:00Z'
name: h2o_feet
time water_level
---- -----------
2015-08-18T00:00:00Z 2.064
2015-08-18T00:06:00Z 2.116
2015-08-18T00:12:00Z 2.028
2015-08-18T00:18:00Z 2.126
2015-08-18T00:24:00Z 2.041
2015-08-18T00:30:00Z 2.051
Example 1: Calculate the moving average of the field values associated with a field key
> SELECT MOVING_AVERAGE("water_level",2) FROM "h2o_feet" WHERE "location" = 'santa_monica' AND time >= '2015-08-18T00:00:00Z' AND time <= '2015-08-18T00:30:00Z'
name: h2o_feet
time moving_average
---- --------------
2015-08-18T00:06:00Z 2.09
2015-08-18T00:12:00Z 2.072
2015-08-18T00:18:00Z 2.077
2015-08-18T00:24:00Z 2.0835
2015-08-18T00:30:00Z 2.0460000000000003
The query returns the rolling average across a two-field-value window for the water_level field key and the h2o_feet measurement.
The first result (2.09) is the average of the first two points in the raw data: (2.064 + 2.116) / 2).
The second result (2.072) is the average of the second two points in the raw data: (2.116 + 2.028) / 2).
Example 2: Calculate the moving average of the field values associated with each field key in a measurement
> SELECT MOVING_AVERAGE(*,3) FROM "h2o_feet" WHERE "location" = 'santa_monica' AND time >= '2015-08-18T00:00:00Z' AND time <= '2015-08-18T00:30:00Z'
name: h2o_feet
time moving_average_water_level
---- --------------------------
2015-08-18T00:12:00Z 2.0693333333333332
2015-08-18T00:18:00Z 2.09
2015-08-18T00:24:00Z 2.065
2015-08-18T00:30:00Z 2.0726666666666667
The query returns the rolling average across a three-field-value window for each field key that stores numerical values in the h2o_feet measurement.
The h2o_feet measurement has one numerical field: water_level.
Example 3: Calculate the moving average of the field values associated with each field key that matches a regular expression
> SELECT MOVING_AVERAGE(/level/,4) FROM "h2o_feet" WHERE "location" = 'santa_monica' AND time >= '2015-08-18T00:00:00Z' AND time <= '2015-08-18T00:30:00Z'
name: h2o_feet
time moving_average_water_level
---- --------------------------
2015-08-18T00:18:00Z 2.0835
2015-08-18T00:24:00Z 2.07775
2015-08-18T00:30:00Z 2.0615
The query returns the rolling average across a four-field-value window for each field key that stores numerical values and includes the word level in the h2o_feet measurement.
Example 4: Calculate the moving average of the field values associated with a field key and include several clauses
> SELECT MOVING_AVERAGE("water_level",2) FROM "h2o_feet" WHERE "location" = 'santa_monica' AND time >= '2015-08-18T00:00:00Z' AND time <= '2015-08-18T00:30:00Z' ORDER BY time DESC LIMIT 2 OFFSET 3
name: h2o_feet
time moving_average
---- --------------
2015-08-18T00:06:00Z 2.072
2015-08-18T00:00:00Z 2.09
The query returns the rolling average across a two-field-value window for the water_level field key in the h2o_feet measurement.
It covers the time range between 2015-08-18T00:00:00Z and 2015-08-18T00:30:00Z and returns results in descending timestamp order.
The query also limits the number of points returned to two and offsets results by three points.
Advanced Syntax
SELECT MOVING_AVERAGE(<function> ([ * | <field_key> | /<regular_expression>/ ]) , N ) [INTO_clause] FROM_clause [WHERE_clause] GROUP_BY_clause [ORDER_BY_clause] [LIMIT_clause] [OFFSET_clause] [SLIMIT_clause] [SOFFSET_clause]
Description of Advanced Syntax
The advanced syntax requires a GROUP BY time() clause and a nested InfluxQL function.
The query first calculates the results for the nested function at the specified GROUP BY time() interval and then applies the MOVING_AVERAGE() function to those results.
MOVING_AVERAGE() supports the following nested functions:
COUNT(),
MEAN(),
MEDIAN(),
MODE(),
SUM(),
FIRST(),
LAST(),
MIN(),
MAX(), and
PERCENTILE().
Examples of Advanced Syntax
Example 1: Calculate the moving average of maximum values
> SELECT MOVING_AVERAGE(MAX("water_level"),2) FROM "h2o_feet" WHERE "location" = 'santa_monica' AND time >= '2015-08-18T00:00:00Z' AND time <= '2015-08-18T00:30:00Z' GROUP BY time(12m)
name: h2o_feet
time moving_average
---- --------------
2015-08-18T00:12:00Z 2.121
2015-08-18T00:24:00Z 2.0885
The query returns the rolling average across a two-value window of maximum water_levels that are calculated at 12-minute intervals.
To get those results, InfluxDB first calculates the maximum water_levels at 12-minute intervals.
This step is the same as using the MAX() function with the GROUP BY time() clause and without MOVING_AVERAGE():
> SELECT MAX("water_level") FROM "h2o_feet" WHERE "location" = 'santa_monica' AND time >= '2015-08-18T00:00:00Z' AND time <= '2015-08-18T00:30:00Z' GROUP BY time(12m)
name: h2o_feet
time max
---- ---
2015-08-18T00:00:00Z 2.116
2015-08-18T00:12:00Z 2.126
2015-08-18T00:24:00Z 2.051
Next, InfluxDB calculates the rolling average across a two-value window using those maximum values.
The first final result (2.121) is the average of the first two maximum values ((2.116 + 2.126) / 2).
NON_NEGATIVE_DERIVATIVE()
Returns the non-negative rate of change between subsequent field values. Non-negative rates of change include positive rates of change and rates of change that equal zero.
Basic Syntax
SELECT NON_NEGATIVE_DERIVATIVE( [ * | <field_key> | /<regular_expression>/ ] [ , <unit> ] ) [INTO_clause] FROM_clause [WHERE_clause] [GROUP_BY_clause] [ORDER_BY_clause] [LIMIT_clause] [OFFSET_clause] [SLIMIT_clause] [SOFFSET_clause]
Description of Basic Syntax
InfluxDB calculates the difference between subsequent field values and converts those results into the rate of change per unit.
The unit argument is an integer followed by a duration literal and it is optional.
If the query does not specify the unit, the unit defaults to one second (1s).
NON_NEGATIVE_DERIVATIVE() returns only positive rates of change or rates of change that equal zero.
NON_NEGATIVE_DERIVATIVE(field_key)
Returns the non-negative rate of change between subsequent field values associated with the field key.
NON_NEGATIVE_DERIVATIVE(/regular_expression/)
Returns the non-negative rate of change between subsequent field values associated with each field key that matches the regular expression.
NON_NEGATIVE_DERIVATIVE(*)
Returns the non-negative rate of change between subsequent field values associated with each field key in the measurement.
NON_NEGATIVE_DERIVATIVE() supports int64 and float64 field value data types.
The basic syntax supports GROUP BY clauses that group by tags but not GROUP BY clauses that group by time.
See the Advanced Syntax section for how to use NON_NEGATIVE_DERIVATIVE() with a GROUP BY time() clause.
Examples of Basic Syntax
See the examples in the DERIVATIVE() documentation.
NON_NEGATIVE_DERIVATIVE() behaves the same as the DERIVATIVE() function but NON_NEGATIVE_DERIVATIVE() returns only positive rates of change or rates of change that equal zero.
Advanced Syntax
SELECT NON_NEGATIVE_DERIVATIVE(<function> ([ * | <field_key> | /<regular_expression>/ ]) [ , <unit> ] ) [INTO_clause] FROM_clause [WHERE_clause] GROUP_BY_clause [ORDER_BY_clause] [LIMIT_clause] [OFFSET_clause] [SLIMIT_clause] [SOFFSET_clause]
Description of Advanced Syntax
The advanced syntax requires a GROUP BY time() clause and a nested InfluxQL function.
The query first calculates the results for the nested function at the specified GROUP BY time() interval and then applies the NON_NEGATIVE_DERIVATIVE() function to those results.
The unit argument is an integer followed by a duration literal and it is optional.
If the query does not specify the unit, the unit defaults to the GROUP BY time() interval.
Note that this behavior is different from the basic syntax’s default behavior.
NON_NEGATIVE_DERIVATIVE() returns only positive rates of change or rates of change that equal zero.
NON_NEGATIVE_DERIVATIVE() supports the following nested functions:
COUNT(),
MEAN(),
MEDIAN(),
MODE(),
SUM(),
FIRST(),
LAST(),
MIN(),
MAX(), and
PERCENTILE().
Examples of Advanced Syntax
See the examples in the DERIVATIVE() documentation.
NON_NEGATIVE_DERIVATIVE() behaves the same as the DERIVATIVE() function but NON_NEGATIVE_DERIVATIVE() returns only positive rates of change or rates of change that equal zero.
Predictors
HOLT_WINTERS()
Returns N number of predicted field values using the Holt-Winters seasonal method.
Use HOLT_WINTERS() to:
- Predict when data values will cross a given threshold
- Compare predicted values with actual values to detect anomalies in your data
Syntax
SELECT HOLT_WINTERS[_WITH-FIT](<function>(<field_key>),<N>,<S>) [INTO_clause] FROM_clause [WHERE_clause] GROUP_BY_clause [ORDER_BY_clause] [LIMIT_clause] [OFFSET_clause] [SLIMIT_clause] [SOFFSET_clause]
Description of Syntax
HOLT_WINTERS(function(field_key),N,S) returns N seasonally adjusted
predicted field values for the specified field key.
The N predicted values occur at the same interval as the GROUP BY time() interval.
If your GROUP BY time() interval is 6m and N is 3 you’ll
receive three predicted values that are each six minutes apart.
S is the seasonal pattern parameter and delimits the length of a seasonal
pattern according to the GROUP BY time() interval.
If your GROUP BY time() interval is 2m and S is 3, then the
seasonal pattern occurs every six minutes, that is, every three data points.
If you do not want to seasonally adjust your predicted values, set S to 0
or 1.
HOLT_WINTERS_WITH_FIT(function(field_key),N,S) returns the fitted values in
addition to N seasonally adjusted predicted field values for the specified field key.
HOLT_WINTERS() and HOLT_WINTERS_WITH_FIT() work with data that occur at
consistent time intervals; the nested InfluxQL function and the
GROUP BY time() clause ensure that the Holt-Winters functions operate on regular data.
HOLT_WINTERS() and HOLT_WINTERS_WITH_FIT() support int64 and float64 field value data types.
Examples
Example 1: Predict field values associated with a field key
Raw Data
Example 1 uses Chronograf to visualize the data.
The example focuses the following subsample of the NOAA_water_database data:
SELECT "water_level" FROM "NOAA_water_database"."autogen"."h2o_feet" WHERE "location"='santa_monica' AND time >= '2015-08-22 22:12:00' AND time <= '2015-08-28 03:00:00'
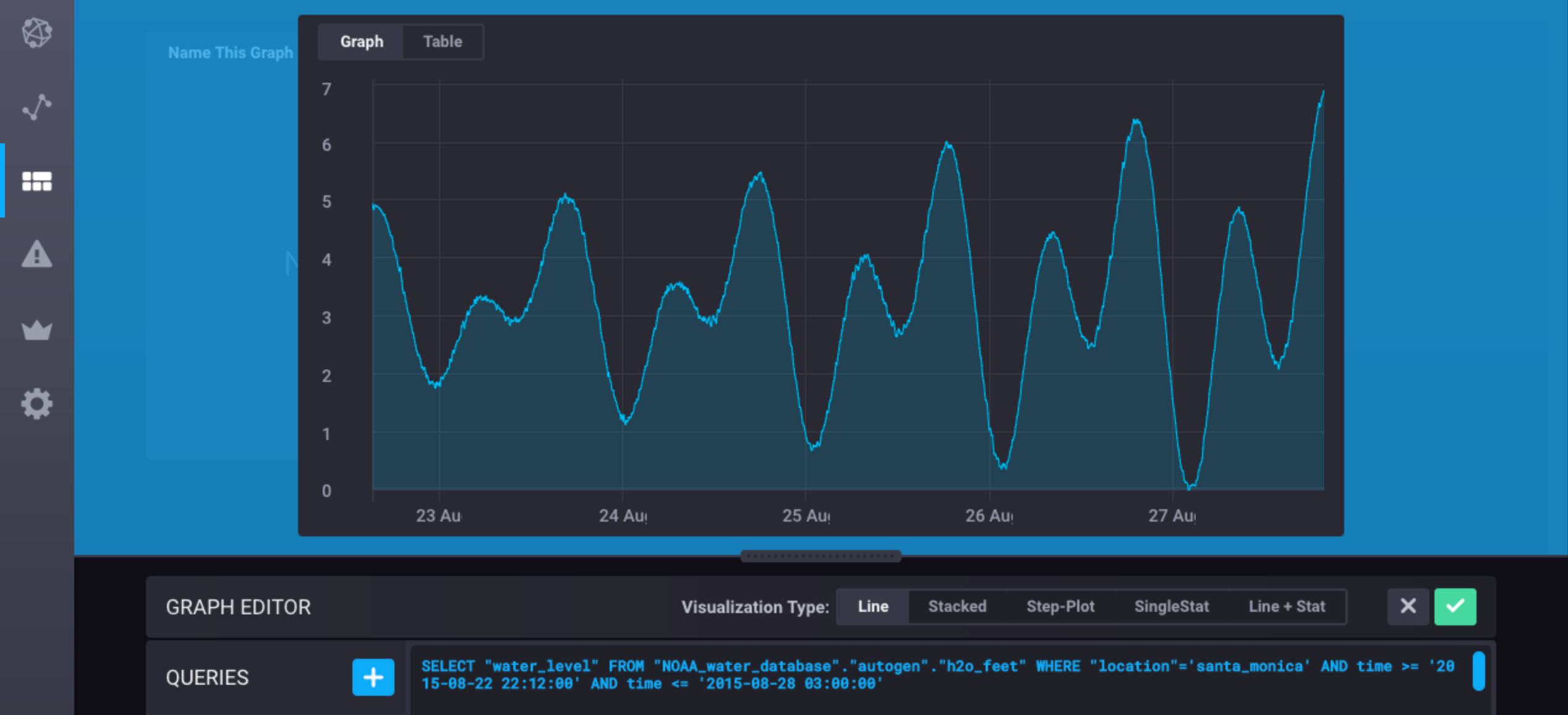
Step 1: Match the Trends of the Raw Data
Write a GROUP BY time() query that matches the general trends of the raw water_level data.
Here, we use the FIRST() function:
SELECT FIRST("water_level") FROM "NOAA_water_database"."autogen"."h2o_feet" WHERE "location"='santa_monica' and time >= '2015-08-22 22:12:00' and time <= '2015-08-28 03:00:00' GROUP BY time(379m,348m)
In the GROUP BY time() clause, the first argument (379m) matches
the length of time that occurs between each peak and trough in the water_level data.
The second argument (348m) is the
offset interval.
The offset interval alters InfluxDB’s default GROUP BY time() boundaries to
match the time range of the raw data.
The blue line shows the results of the query:
Step 2: Determine the Seasonal Pattern
Identify the seasonal pattern in the data using the information from the
query in step 1.
Focusing on the blue line in the graph below, the pattern in the water_level data repeats about every 25 hours and 15 minutes.
There are four data points per season, so 4 is the seasonal pattern argument.
Step 3: Apply the HOLT_WINTERS() function
Add the Holt-Winters function to the query.
Here, we use HOLT_WINTERS_WITH_FIT() to view both the fitted values and the predicted values:
SELECT HOLT_WINTERS_WITH_FIT(FIRST("water_level"),10,4) FROM "NOAA_water_database"."autogen"."h2o_feet" WHERE "location"='santa_monica' AND time >= '2015-08-22 22:12:00' AND time <= '2015-08-28 03:00:00' GROUP BY time(379m,348m)
In the HOLT_WINTERS_WITH_FIT() function, the first argument (10) requests 10 predicted field values.
Each predicted point is 379m apart, the same interval as the first argument in the GROUP BY time() clause.
The second argument in the HOLT_WINTERS_WITH_FIT() function (4) is the seasonal pattern that we determined in the previous step.
The blue line shows the results of the query:
Common Issues with HOLT_WINTERS()
Issue 1: HOLT_WINTERS() and receiving fewer than N points
In some cases, users may receive fewer predicted points than
requested by the N parameter.
That behavior occurs when the math becomes unstable and cannot forecast more
points.
It implies that either HOLT_WINTERS() is not suited for the dataset or that
the seasonal adjustment parameter is invalid and is confusing the algorithm.
Other
Sample Data
The data used in this document are available for download on the Sample Data page.
General Syntax for Functions
Specify Multiple Functions in the SELECT Clause
Syntax
SELECT <function>(),<function>() FROM_clause [...]
Description of Syntax
Separate multiple functions in one SELECT statement with a comma (,).
Examples
Example 1: Calculate the mean and median field values in one query
> SELECT MEAN("water_level"),MEDIAN("water_level") FROM "h2o_feet"
name: h2o_feet
time mean median
---- ---- ------
1970-01-01T00:00:00Z 4.442107025822522 4.124
The query returns the average and median field values in the water_level field key.
Example 2: Calculate the mode of two fields in one query
> SELECT MODE("water_level"),MODE("level description") FROM "h2o_feet"
name: h2o_feet
time mode mode_1
---- ---- ------
1970-01-01T00:00:00Z 2.69 between 3 and 6 feet
The query returns the mode field values for the water_level field key and for the level description field key.
The water_level mode is in the mode column and the level description mode is in the mode_1 column.
The system can’t return more than one column with the same name so it renames the second mode column to mode_1.
See Rename the Output Field Key for how to configure the output column headers.
Example 3: Calculate the minimum and maximum field values in one query
> SELECT MIN("water_level"), MAX("water_level") [...]
name: h2o_feet
time min max
---- --- ---
1970-01-01T00:00:00Z -0.61 9.964
The query returns the minimum and maximum field values in the water_level field key.
Notice that the query returns 1970-01-01T00:00:00Z, InfluxDB’s null-timestamp equivalent, as the timestamp.
MIN() and MAX() are selector functions; when a selector function is the only function in the SELECT clause, it returns a specific timestamp.
Because MIN() and MAX() return two different timestamps (see below), the system overrides those timestamps with the null timestamp equivalent.
> SELECT MIN("water_level") FROM "h2o_feet"
name: h2o_feet
time min
---- ---
2015-08-29T14:30:00Z -0.61 <--- Timestamp 1
> SELECT MAX("water_level") FROM "h2o_feet"
name: h2o_feet
time max
---- ---
2015-08-29T07:24:00Z 9.964 <--- Timestamp 2
Rename the Output Field Key
Syntax
SELECT <function>() AS <field_key> [...]
Description of Syntax
By default, functions return results under a field key that matches the function name.
Include an AS clause to specify the name of the output field key.
Examples
Example 1: Specify the output field key
> SELECT MEAN("water_level") AS "dream_name" FROM "h2o_feet"
name: h2o_feet
time dream_name
---- ----------
1970-01-01T00:00:00Z 4.442107025822522
The query returns the average field value of the water_level field key and renames the output field key to dream_name.
Without the AS clause, the query returns mean as the output field key:
> SELECT MEAN("water_level") FROM "h2o_feet"
name: h2o_feet
time mean
---- ----
1970-01-01T00:00:00Z 4.442107025822522
Example 2: Specify the output field key for multiple functions
> SELECT MEDIAN("water_level") AS "med_wat",MODE("water_level") AS "mode_wat" FROM "h2o_feet"
name: h2o_feet
time med_wat mode_wat
---- ------- --------
1970-01-01T00:00:00Z 4.124 2.69
The query returns the median and mode field values for the water_level field key and renames the output field keys to med_wat and mode_wat.
Without the AS clauses, the query returns median and mode as the output field keys:
> SELECT MEDIAN("water_level"),MODE("water_level") FROM "h2o_feet"
name: h2o_feet
time median mode
---- ------ ----
1970-01-01T00:00:00Z 4.124 2.69
Change the Values Reported for Intervals with no Data
By default, queries with an InfluxQL function and a GROUP BY time() clause report null values for intervals with no data.
Include fill() at the end of the GROUP BY clause to change that value.
See Data Exploration for a complete discussion of fill().
Common Issues with Functions
The following sections describe frequent sources of confusion with all functions, aggregation functions, and selector functions. See the function-specific documentation for common issues with individual functions:
All Functions
Issue 1: Nesting functions
Some InfluxQL functions support nesting in the SELECT clause:
COUNT()withDISTINCT()CUMULATIVE_SUM()DERIVATIVE()DIFFERENCE()ELAPSED()MOVING_AVERAGE()NON_NEGATIVE_DERIVATIVE()HOLT_WINTERS()andHOLT_WINTERS_WITH_FIT()
For other functions, use InfluxQL’s subqueries to nest functions in the FROM clause.
See the Data Exploration page more on using subqueries.
Issue 2: Querying time ranges after now()
Most SELECT statements have a default time range between 1677-09-21 00:12:43.145224194 and 2262-04-11T23:47:16.854775806Z UTC.
For SELECT statements with an InfluxQL function and a GROUP BY time() clause, the default time
range is between 1677-09-21 00:12:43.145224194 UTC and now().
To query data with timestamps that occur after now(), SELECT statements with
an InfluxQL function and a GROUP BY time() clause must provide an alternative upper bound in the
WHERE clause.
See the Frequently Asked Questions page for an example.
Aggregation Functions
Issue 1: Understanding the returned timestamp
A query with an aggregation function and no time range in the WHERE clause returns epoch 0 (1970-01-01T00:00:00Z) as the timestamp.
InfluxDB uses epoch 0 as the null timestamp equivalent.
A query with an aggregate function that includes a time range in the WHERE clause returns the lower time bound as the timestamp.
Examples
Example 1: Use an aggregate function without a specified time range
> SELECT SUM("water_level") FROM "h2o_feet"
name: h2o_feet
time sum
---- ---
1970-01-01T00:00:00Z 67777.66900000004
The query returns InfluxDB’s null timestamp equivalent (epoch 0: 1970-01-01T00:00:00Z) as the timestamp.
SUM() aggregates points across several timestamps and has no single timestamp to return.
Example 2: Use an aggregate function with a specified time range
> SELECT SUM("water_level") FROM "h2o_feet" WHERE time >= '2015-08-18T00:00:00Z'
name: h2o_feet
time sum
---- ---
2015-08-18T00:00:00Z 67777.66900000004
The query returns the lower time bound (WHERE time >= '2015-08-18T00:00:00Z') as the timestamp.
Example 3: Use an aggregate function with a specified time range and a GROUP BY time() clause
> SELECT SUM("water_level") FROM "h2o_feet" WHERE time >= '2015-08-18T00:00:00Z' AND time <= '2015-08-18T00:18:00Z' GROUP BY time(12m)
name: h2o_feet
time sum
---- ---
2015-08-18T00:00:00Z 20.305
2015-08-18T00:12:00Z 19.802999999999997
The query returns the lower time bound for each GROUP BY time() interval as the timestamps.
Issue 2: Mixing aggregation functions with non-aggregates
Aggregation functions do not support specifying standalone field keys or tag keys in the SELECT clause.
Aggregation functions return a single calculated value and there is no obvious single value to return for any unaggregated fields or tags.
Including a standalone field key or tag key with an aggregation function in the SELECT clause returns an error:
> SELECT SUM("water_level"),"location" FROM "h2o_feet"
ERR: error parsing query: mixing aggregate and non-aggregate queries is not supported
Issue 3: Getting slightly different results
For some aggregation functions, executing the same function on the same set of float64 points may yield slightly different results. InfluxDB does not sort points before it applies the aggregation function; that behavior can cause small discrepancies in the query results.
Selector Functions
Issue 1: Understanding the returned timestamp
The timestamps returned by selector functions depend on the number of functions in the query and on the other clauses in the query:
A query with a single selector function, a single field key argument, and no GROUP BY time() clause returns the timestamp for the point that appears in the raw data.
A query with a single selector function, multiple field key arguments, and no GROUP BY time() clause returns the timestamp for the point that appears in the raw data or InfluxDB’s null timestamp equivalent (epoch 0: 1970-01-01T00:00:00Z).
A query with more than one function and no time range in the WHERE clause returns InfluxDB’s null timestamp equivalent (epoch 0: 1970-01-01T00:00:00Z).
A query with more than one function and a time range in the WHERE clause returns the lower time bound as the timestamp.
A query with a selector function and a GROUP BY time() clause returns the lower time bound for each GROUP BY time() interval.
Note that the SAMPLE() function behaves differently from other selector functions when paired with the GROUP BY time() clause.
See Common Issues with SAMPLE() for more information.
Examples
Example 1: Use a single selector function with a single field key and without a specified time range
> SELECT MAX("water_level") FROM "h2o_feet"
name: h2o_feet
time max
---- ---
2015-08-29T07:24:00Z 9.964
> SELECT MAX("water_level") FROM "h2o_feet" WHERE time >= '2015-08-18T00:00:00Z'
name: h2o_feet
time max
---- ---
2015-08-29T07:24:00Z 9.964
The queries return the timestamp for the maximum point that appears in the raw data.
Example 2: Use a single selector function with multiple field keys and without a specified time range
> SELECT FIRST(*) FROM "h2o_feet"
name: h2o_feet
time first_level description first_water_level
---- ----------------------- -----------------
1970-01-01T00:00:00Z between 6 and 9 feet 8.12
> SELECT MAX(*) FROM "h2o_feet"
name: h2o_feet
time max_water_level
---- ---------------
2015-08-29T07:24:00Z 9.964
The first query returns InfluxDB’s null timestamp equivalent (epoch 0: 1970-01-01T00:00:00Z) as the timestamp.
FIRST(*) returns two timestamps (one for each field key in the h2o_feet measurement) so the system overrides those timestamps with the null timestamp equivalent.
The second query returns the timestamp for the maximum point that appears in the raw data.
MAX(*) returns one timestamp (the h2o-feet measurement has only one numerical field) so the system does not overwrite the original timestamp.
Example 3: Use a selector function with another function and without a specified time range
> SELECT MAX("water_level"),MIN("water_level") FROM "h2o_feet"
name: h2o_feet
time max min
---- --- ---
1970-01-01T00:00:00Z 9.964 -0.61
The query returns InfluxDB’s null timestamp equivalent (epoch 0: 1970-01-01T00:00:00Z) as the timestamp.
The MAX() and MIN() functions return different timestamps so the system has no single timestamp to return.
Example 4: Use a selector function with another function and with a specified time range
> SELECT MAX("water_level"),MIN("water_level") FROM "h2o_feet" WHERE time >= '2015-08-18T00:00:00Z'
name: h2o_feet
time max min
---- --- ---
2015-08-18T00:00:00Z 9.964 -0.61
The query returns the lower time bound (WHERE time >= '2015-08-18T00:00:00Z') as the timestamp.
Example 5: Use a selector function with a GROUP BY time() clause
> SELECT MAX("water_level") FROM "h2o_feet" WHERE time >= '2015-08-18T00:00:00Z' AND time <= '2015-08-18T00:18:00Z' GROUP BY time(12m)
name: h2o_feet
time max
---- ---
2015-08-18T00:00:00Z 8.12
2015-08-18T00:12:00Z 7.887
The query returns the lower time bound for each GROUP BY time() interval as the timestamp.